003.蓝图、模型与CodeFirst
1 应用、蓝图与视图函数
在flask中,app就像一个插座,我们可以把一个一个模块插到app中进行使用,flask提供了一种机制叫做蓝图(bulueprint),它就相当于一个一个大的模块,下面可以整合各种资源
备注:flask是允许同时存在多个app的
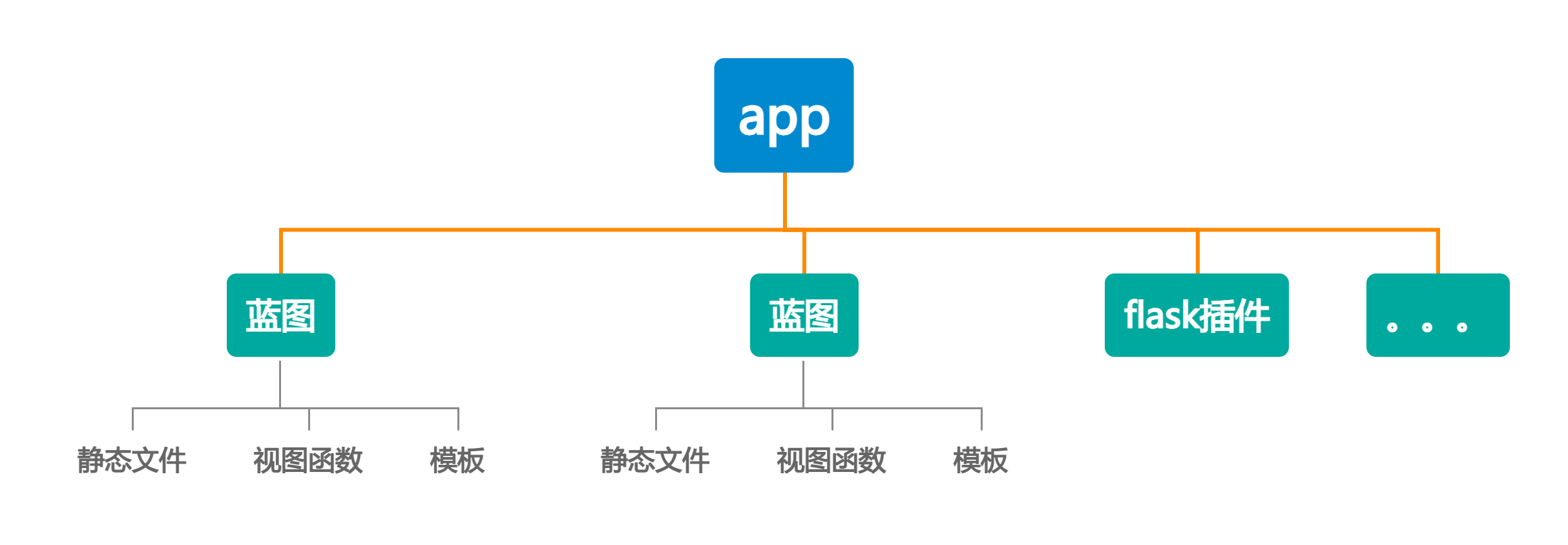
回到我们前文创建的层级,其中web文件夹就是蓝图
|- app # flask应用对象
|__ web # 蓝图
|___ book.py
当然,一个大型业务系统中,通常会存在大量的蓝图,将他们堆叠在启动文件中,同样也会造成代码繁多导致维护困难的情况发生,此时就需要借助,python的软件包进行了,将初始化的代码放入软件包的__init__.py文件,即可在加载软件包的时候同步初始化代码
app/init.py
from flask import Flask
import config
def create_app():
app = Flask(__name__) # 将初始化app的代码放到app包的__init__.py文件中
app.config.from_object(config) # 加载配置文件
return app
from app import create_app
app = create_app() # 即可一键加载配置文件完成初始化
if __name__ == '__main__':
app.run(host='0.0.0.0',port=82)
2 用蓝图注册视图函数
首先我们在book.py文件中将函数注册在蓝图中
import helper
from yushu_book import YushuBook
from flask import jsonify
# 导入蓝图
from flask import Blueprint
web = Blueprint('web', __name__, url_prefix='/web')
# 把函数注册到蓝图
@web.route("/book/search/<q>/", endpoint='search')
def search(q,page=1):
isbn_or_key = helper.is_isbn_or_key(q)
if isbn_or_key == 'isbn':
result = YushuBook.search_by_isbn(q)
else:
result = YushuBook.search_by_keyword(q,page)
return jsonify(result)
Blueprint参数说明:
'web':这是蓝图的名称,用于在Flask内部标识这个蓝图。这个名称必须是唯一的,不能与其他蓝图重复。
__name__:这是蓝图所在的模块名称。通常传入__name__,让Flask自动确定蓝图的位置。这个参数用于帮助Flask定位模板和静态文件。
url_prefix='/web':URL前缀(可不添加),所有注册到这个蓝图的路由都会自动加上这个前缀。例如,如果你定义了一个路由/book,实际访问的URL将会是/web/book。
app/init.py
from flask import Flask
import config
def create_app():
app = Flask(__name__)
app.config.from_object(config)
register_blueprint(app) # 调用register_blueprint函数实现注册蓝图
return app
def register_blueprint(app):
# 从app.web.book模块导入web蓝图
from app.web.book import web
# 将web蓝图注册到Flask应用中
app.register_blueprint(web)
我们在此使用了一个register_blueprint(app)函数专门用于添加蓝图,首先将book.py中注册的蓝图web导入到函数中,然后使用app.register_blueprint(web)注册到app中
访问地址:http://url/蓝图地址/路径
访问地址:http://192.168.31.20:82/web/book/search/python/
3 单蓝图多模块拆分视图函数
我们前文的操作已经将蓝图从main.py转移到了其他文件中去,但这只完成了视图函数的迁移,并没有完成拆分,甚至说拆分都不完全
例如:我们现在需要在web蓝图下新建一个user.py文件,引入web蓝图后发现访问该代码为404,没有注册成功
from . import web
@web.route('/user/', endpoint='user')
def user():
pass
回到app/__init__.py文件中,发现register_blueprint函数中导入的是app.web.book,觉得不合理,但发现如果导入from app.web import web又会导致路由注册失败
from flask import Flask
import config
def create_app():
# 创建Flask应用实例,__name__用于确定应用根路径
app = Flask(__name__)
# 从config模块加载应用配置
app.config.from_object(config)
# 注册蓝图(在register_blueprint函数中实现)
register_blueprint(app)
# 返回创建完成的Flask应用实例
return app
def register_blueprint(app):
# 从app.web.book模块导入web蓝图
from app.web.book import web # 此处导入的为app.web.book
# 将web蓝图注册到Flask应用中
app.register_blueprint(web)
根据查阅资料得知,在app/web/__init__.py中,导入book和user
# 导入蓝图
from flask import Blueprint
web = Blueprint('web', __name__, url_prefix='/web')
from app.web import book
from app.web import user
然后在app/__init__.py文件中,就可以导入from app.web import web进行注册路由了,在此就完成了一个蓝图指向多个视图函数
4 request对象
前文我们使用@web.route("/book/search/<q>/")中的q进行传参,让查询内容直接内置于url中,但这终究不够优雅。我们计划将查询从http://url/book/search/python/变成http://url/book/search?q=python
我们之前接触过一个由flask定义管理的函数response,他的主要功能是定义一些返回数据,而他的同胞兄弟同样由flask定义管理的request则可以用于获取HTTP的请求信息,其中就包括参数信息
import helper
from yushu_book import YushuBook
from flask import jsonify
from . import web
from flask import request # 导入request
@web.route("/book/search/") # 把参数部分去掉
def search():
q = request.args['q'] # 获取q的参数
page = request.args['page'] # 获取page的参数
isbn_or_key = helper.is_isbn_or_key(q)
if isbn_or_key == 'isbn':
result = YushuBook.search_by_isbn(q)
else:
result = YushuBook.search_by_keyword(q,page)
return jsonify(result)
在访问的时候,我们使用http://10.151.0.139:82/web/book/search/?q=python&page=1构成url进行访问
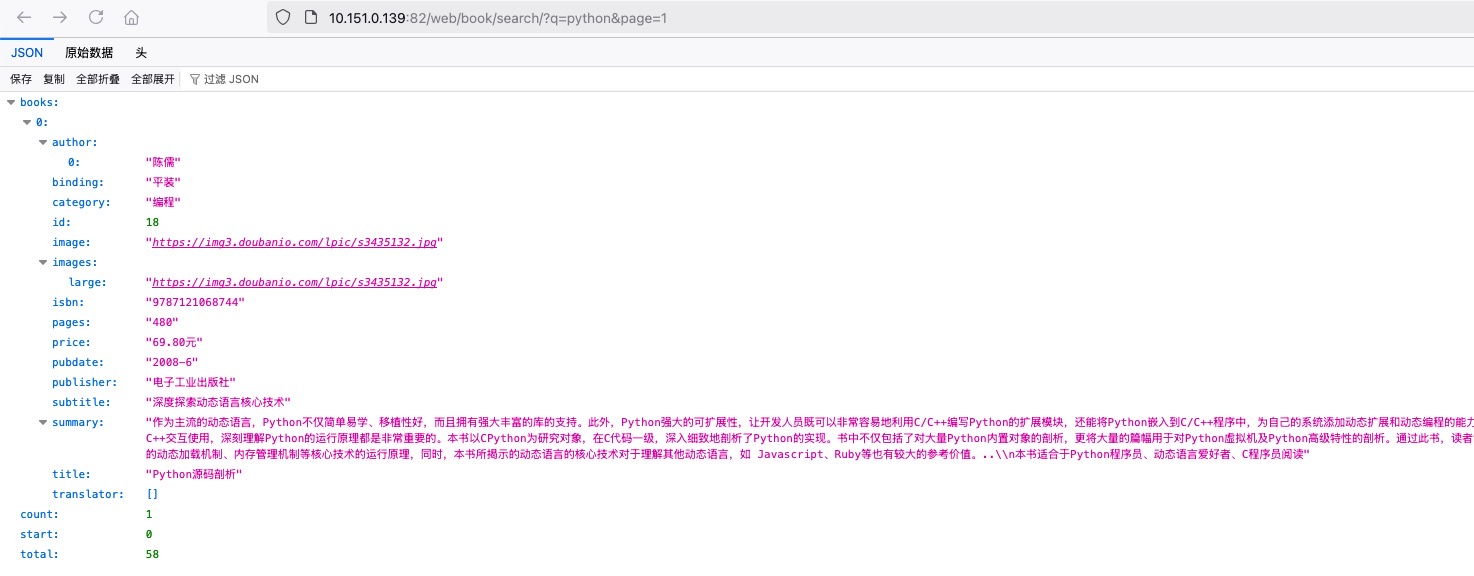
在这里需要注意的是request.args['q']的值其实是一个不可变的字典MultiDict,具体参考可变不可变章节
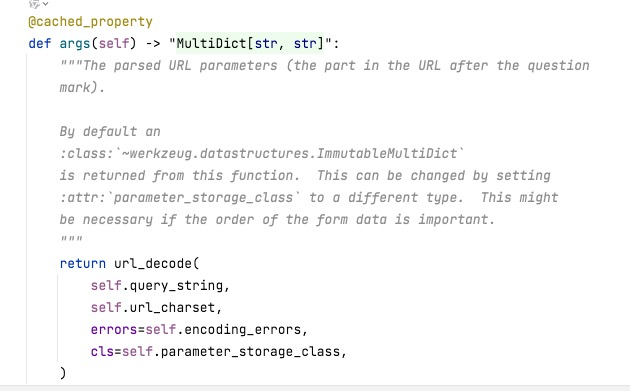
它可以通过字典的方式进行读取,并且它可以通过request.args.to_dict()将它变成一个可变的字典
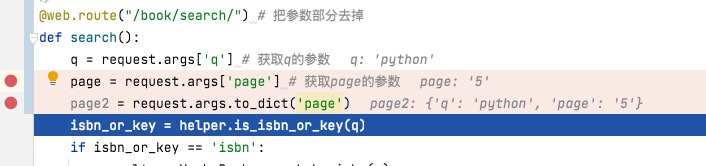
注意:由于request是由flask代理得到,所以只能有蓝图的视图或者HTTP请求进行触发
5 WTForms参数验证
总所周知,漏洞有很大程度就是因为能够输入恶意的代码被系统得到执行,所以需要我们使用大量的判断对输入内容进行合法性校验
基本校验案例:
q:至少要有一个字符、长度限制
page:正整数 长度限制
按照我们以前所学知识,可以使用大量的判断语句进行合法性校验,也可以使用正则表达式进行合法性校验,而在flask中,提供了模块插件帮助我们完成这个工作,我们可以使用第三方的插件进行参数的校验和管理,wtforms就是其中一种,在命令行窗口中进行安装pipenv install wtforms
参数验证是一个至关重要的环节,他决定了用户输入是否合法,所以根据mvc分层模型,我们将其进行独立分层,独立为验证层
5.1 验证器基本用法
在此我们将验证层放到app层级之下,取名为forms,在forms软件包中,创建book.py,表明专为web/book.py进行验证的插件工具
|__main.py
|__cms
|__web
| |__book.py
|__forms # 验证层
| |__book.py # 验证 web/book.py 的文件
|__config.py
首先我们写一下验证层forms/book.py的代码,然后将验证层部署到web/book.py就能看到结果了
forms/book.py
from wtforms import Form,StringField,IntegerField # 导入Form验证工具 以及 StringField验证字符串 IntegerField验证整数
from wtforms.validators import Length,NumberRange # 导入工具插件 Length验证长度范围 NumberRange验证整数范围
class SearchForm(Form):
q = StringField(validators=[Length(min=1,max=30)]) # 验证字符串 输入结果要求:长度最小为1 最大为30
page = IntegerField(validators=[NumberRange(min=1,max=999)],default=1) # 验证整数 输入结果要求 最小整数为1 最大整数为999 如果未输入此项数据默认为1
web/book.py
import helper
from yushu_book import YushuBook
from flask import jsonify
from . import web
from flask import request
from app.forms.book import SearchForm
@web.route("/book/search/")
def search():
# 验证层
form = SearchForm(request.args)
if form.validate(): # 返回为真,说明q和page都通过了验证
q = form.q.data.strip() # 从验证层取到q,并且去掉前后的空格
page = form.page.data # 在form中给了page默认值,如果从form中取可以获得,从request从取就拿不到默认值
isbn_or_key = helper.is_isbn_or_key(q)
if isbn_or_key == 'isbn':
result = YushuBook.search_by_isbn(q)
else:
result = YushuBook.search_by_keyword(q,page)
return jsonify(result)
else:
return jsonify({'msg':'参数校验失败'})
5.2 验证器错误返回
如果wtforms验证不通过,不会直接抛出异常,而是返回False,然后将信息显示在errors中
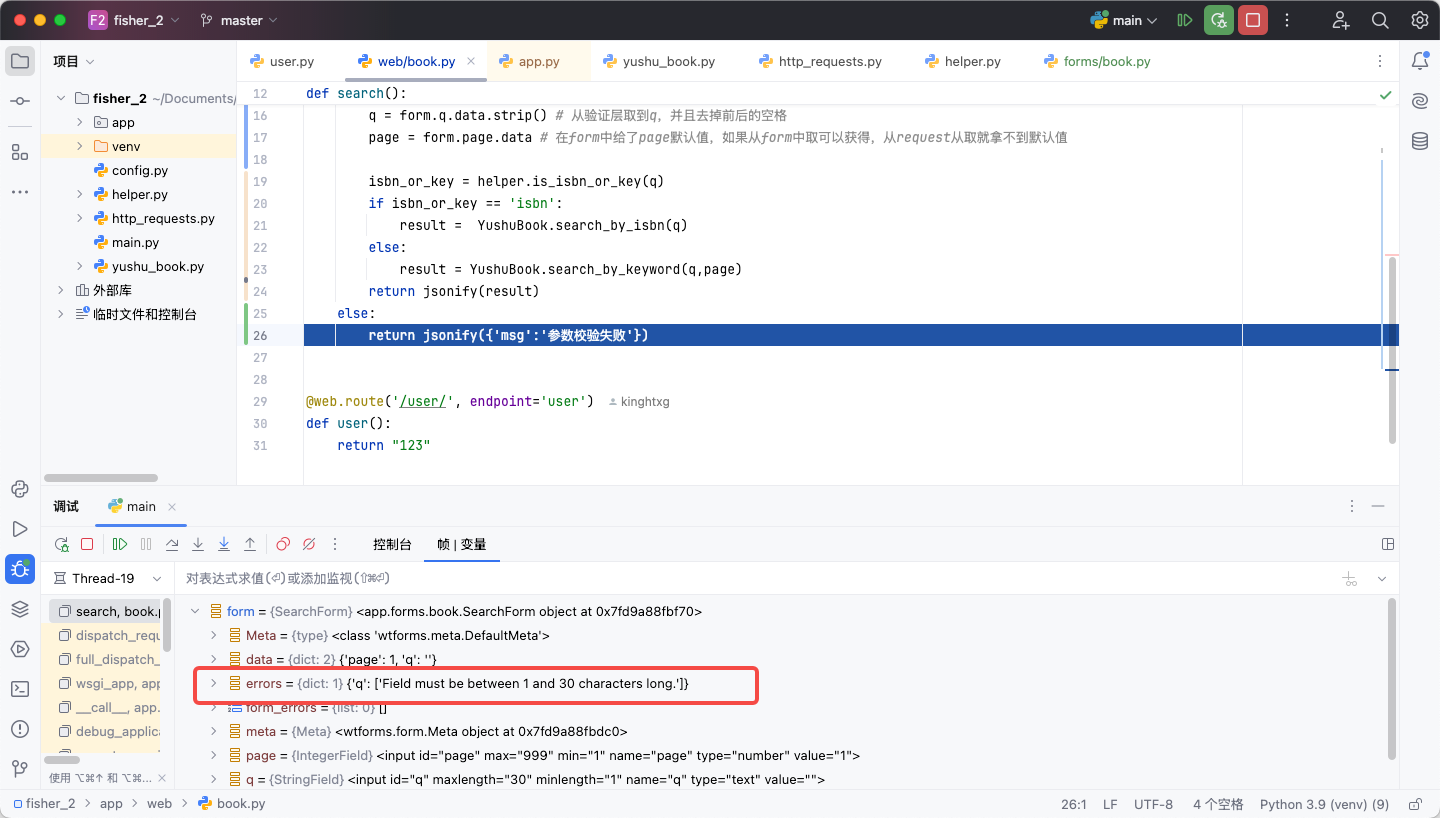
所以应对错误输出可以修改代码为return jsonify(form.errors),在客户端就能看到参数报错的具体原因
注意:这个错误提示是可以自定义的!在定义wtfrom的时候就可以自定义报错
forms/book.py
from wtforms import Form,StringField,IntegerField
from wtforms.validators import Length,NumberRange
class SearchForm(Form):
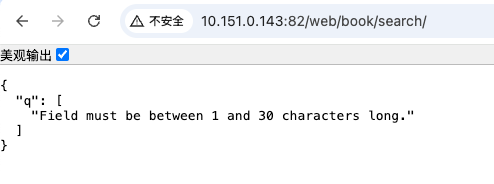
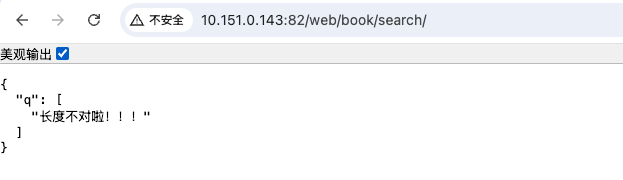
q = StringField(validators=[Length(min=1,max=30,message="长度不对啦!!!")]) # message修改报错返回
page = IntegerField(validators=[NumberRange(min=1,max=999)],default=1)
所展现出来的效果就是
5.3 验证器空格过滤
我们经过一个小测试,如果给q传参使用空格是否生效?
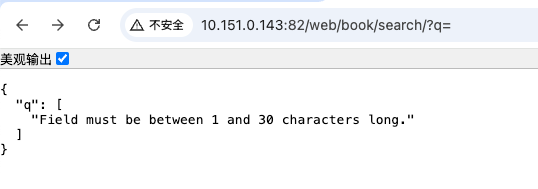
http://10.151.0.143:82/web/book/search/?q=会被验证器直接返回过滤,但是这是因为没有进行空格编码的情况,如果传入的是http://10.151.0.143:82/web/book/search/?q=%20或者http://10.151.0.143:82/web/book/search/?q=%20&page=1浏览器会将空格进行url编码转换成%20,验证器就会让他通过验证了
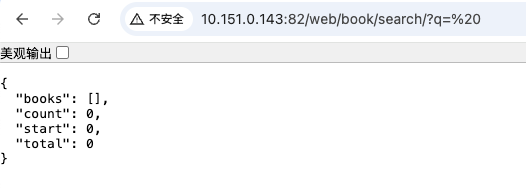
这个问题非常好解决,我们为验证器增加一个插件DataRequired
from wtforms import Form,StringField,IntegerField
from wtforms.validators import Length, NumberRange, DataRequired # 导入插件DataRequired
class SearchForm(Form):
q = StringField(validators=[DataRequired(),Length(min=1,max=30)]) # 增加插件DataRequired()
page = IntegerField(validators=[NumberRange(min=1,max=999)],default=1)
访问时插件就会返回错误,并且告诉他,这是一个必填项
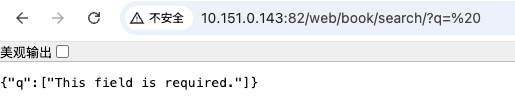
同样他也是支持message的,q = StringField(validators=[DataRequired(message="不能填写空格"),Length(min=1,max=30)])
6 拆分配置文件
在开发过程中,我们发现越来越多的数据可以存放于config.py便于事后调整,根据大佬们的开发习惯,我们将配置文件转移到web目录下方便管理,并且将config.py文件一分为二。
数据库账号密码、appkey等机密文件放置于secure.py,在生产环节中应该关闭的配置也应该放置于secure.py。
不涉及生产环节和开发环节区别的非机密配置放置于setting.py
在部署或者上传源代码时,setting.py文件可用于直接使用,而secure.py文件需要修改和脱敏使用。
web/init.py
from flask import Flask
from app import secure
def create_app():
app = Flask(__name__)
# 从config模块加载应用配置
app.config.from_object('app.secure')
app.config.from_object('app.setting')
register_blueprint(app)
# 返回创建完成的Flask应用实例
return app
def register_blueprint(app):
# 从app.web.book模块导入web蓝图
from app.web import web
from app.user import user
# 将web蓝图注册到Flask应用中
app.register_blueprint(web)
app.register_blueprint(user)
7 Model First、Database First与Code First
大多数的外部API都是有频率限制的,我们需要尽量的减少我们向外部API发送HTTP请求的次数,以减少我们被封IP的这样的风险,所以我们需要使用数据库将查询结果在本地保留一份,再次查询已经保留过的数据只需要调用数据库的内容即可
我们对项目的代码再次做一个调整,让他更符合项目的结构
我们app文件夹中放一个libs,把helper.py和http_requests.py放进去,然后把相关导入全部都修改一下from app.libs.http_requests import HTTP
以后我们都libs文件夹就存放一些自定义的模块
把app/web/yushu_book.py也换一个位置,因为它从api访问数据返回的过程很像是一个爬虫,为了增加代码的复用性和命名的直观性,把爬虫相关内容独立成一个包,命名为app/spider,把yushu_book.py放到spider中
回归本节课重点:
创建数据库表结构分为三种方式:Model First、Database First与Code First
7.1 Database First
Database First通常是在数据库管理工具中通过图形界面或SQL语句完成。一旦数据库结构确定,开发者可以使用如Entity Framework等ORM(对象关系映射)工具,将数据库的结构映射到应用程序的代码模型中,自动生成实体类和上下文类,从而减少手动编写代码的工作量。
说人话:Database First就是在某个数据库管理软件例如DataGrip的可视化界面中手动创建表格那样创建数据库
7.2 Model First
Model First通常涉及到使用建模工具(如 ER 图编辑器)来定义实体(表)、属性(字段)以及实体之间的关系。这些模型可以是图形化的,直观地展示了表与表之间的关联,以及字段与字段之间的关系。一旦模型设计完成,可以使用特定的工具或框架(如 Entity Framework)将这个模型转换为实际的数据库结构和相应的代码,从而实现数据模型到数据库和应用程序代码的映射。
7.3 Code First
7.3.1 Code First使用方法
作为程序编写者,我们最常用的方式就是通过Code First来编写表结构,即在MVC中的M模型层,CodeFirst就是通过新建的一个个的模型,在数据库里生成一张张的数据表。
做模型设计的时候,一定要忘记数据库数据表的存在。设计模型的思维应该围绕着业务模型,比如Book就是业务模型,其属性应直接反映业务需求(如书名、作者、ISBN号、库存状态等),而非数据库字段的物理存储细节。
我们在app下创建模型的包models,将book模型创建在book.py文件中
class Book():
id = None
title = ''
author = ''
isbn = ''
price = 0
binding = ''
也就是将书的基本信息:id、书名、作者、isbn编号、价格、封装方式,定义成类,我们现在就需要使用sqlalchemy这个工具,将它解析到数据库中生成数据表
注意:
flask属于微框架,框架本身只提供核心功能,更多的功能需要安装第三方组件完成,sqlalchemy这个工具并非flask组件,但flask将这个工具进行了封装,使其API更人性化,flask中有大量封装第三方的代码,例如:flask_WTFORMS封装的WTFORMS,甚至路由实现也是封装的基于WSGI的第三方函数库werkzeug实现的
安装flask-sqlalchemy:
pipenv install flask-sqlalchemy
然后我们通过pipenv graph可以查看已经安装的库
(venv) yangzhichao@yangzhichaodeMacBook-Air fisher_2 % pipenv graph
Courtesy Notice:
Pipenv found itself running within a virtual environment, so it will automatically use that
environment, instead of creating its own for any project. You can set
PIPENV_IGNORE_VIRTUALENVS=1 to force pipenv to ignore that environment and create its own instead.
You can set PIPENV_VERBOSITY=-1 to suppress this warning.
Flask-SQLAlchemy==3.1.1
├── Flask
│ ├── blinker
│ ├── click
│ ├── importlib_metadata
│ │ └── zipp
│ ├── itsdangerous
│ ├── Jinja2
│ │ └── MarkupSafe
│ └── Werkzeug
│ └── MarkupSafe
└── SQLAlchemy # 再此可以看到Flask-SQLAlchemy是以SQLAlchemy为基础
├── greenlet
└── typing_extensions
WTForms==3.2.1
└── MarkupSafe
修改完善一下代码
from sqlalchemy import Column, Integer, String
class Book():
# 主键字段,唯一标识每本书(必填项)
# primary_key=True 表示将此列设为主键
# autoincrement=True 启用自增特性(通常与主键搭配使用)
id = Column(Integer, primary_key=True, autoincrement=True)
# 书名(必填项)
# String(50) 限定最大长度50字符,防止数据库存储超长数据
# nullable=False 表示该字段不可为空(强制约束)
title = Column(String(50), nullable=False)
# 作者(带默认值)
# default="未名" 当未提供作者信息时,自动填充默认值
# String(30) 预留30字符空间(建议根据实际需求调整长度)
author = Column(String(30), default="未名")
# 装订类型(平装/精装等)
# 未设置约束时,默认 nullable=True(允许空值)
binding = Column(String(20))
# 出版社信息
# 无默认值且允许为空,适合非必填字段
publisher = Column(String(50))
# 价格(当前用字符串存储,后续可优化为Numeric类型)
# String(20) 暂时兼容带货币符号的格式(如"¥59.90")
price = Column(String(20))
# 页数(整数类型)
# 无约束时允许空值,适合可选字段
pages = Column(Integer)
# 出版日期(当前用字符串存储,后续可改用Date类型)
# 例如存储"2023-08-01"格式的日期字符串
pubdate = Column(String(20))
# ISBN 国际标准书号(唯一标识)
# unique=True 强制全表唯一,避免重复录入
# nullable=False 配合业务规则保证数据完整性
isbn = Column(String(15), nullable=False, unique=True)
# 图书摘要(长文本)
# String(1000) 适合中等长度文本
summary = Column(String(1000))
# 封面图片路径(URL或本地路径)
# String(500) 限定路径长度
image = Column(String(500))
接下来我们要使用SQLALchemy这个库进行数据表的创建工作
from sqlalchemy import Column, Integer, String
from flask_sqlalchemy import SQLAlchemy # 从封装好的flask_sqlalchemy加载SQLAlchemy
db = SQLAlchemy() # 实例化SQLAlchemy
class Book(db.Model): # 让模型类继承db.Model
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
author = Column(String(30), default="未名")
binding = Column(String(20))
publisher = Column(String(50))
price = Column(String(20))
pages = Column(Integer)
pubdate = Column(String(20))
isbn = Column(String(15), nullable=False, unique=True)
summary = Column(String(1000))
image = Column(String(50))
我们之前提到过,app就像一个插座,我们需要将SQLLchemy实例化的db像是插头一样插在app上,这一步在app/__init__.py 中操作
from flask import Flask
from app import secure
from app.models.book import db # 导入实例化SQLAlchemy
def create_app():
app = Flask(__name__)
app.config.from_object('app.secure')
app.config.from_object('app.setting')
register_blueprint(app)
db.init_app(app) # 让db和核心对象关联起来
db.create_all() # 调用db将数据模型映射到数据表中(没有这个步骤无法写入数据表)
return app
def register_blueprint(app):
from app.web import web
from app.user import user
app.register_blueprint(web)
app.register_blueprint(user)
既然是操作数据库进行,那么我们就需要在配置链接数据库的账号密码,前文提到过,敏感信息配置需要放在app/secure.py中
DEBUG = True
# cymysql需要安装 pip install cymysql
# SQLALCHEMY_DATABASE_URI名字是不能修改的 字符串格式为 数据库类型+连接驱动://数据库账号:数据库密码@数据库地址:端口/数据库名
SQLALCHEMY_DATABASE_URI = 'mysql+cymysql://root:0qKy8C3vNcABrL@172.16.2.73:3306/fisher'
现在我们就可以运行程序,将文件写入其中了
但是,好像报错了!!!
Traceback (most recent call last):
File "D:\WORK\code\yushu_book.git\main.py", line 4, in <module>
app = create_app()
File "D:\WORK\code\yushu_book.git\app\__init__.py", line 13, in create_app
db.create_all() # 调用db将数据模型映射到数据表中
~~~~~~~~~~~~~^^
File "C:\Users\41935\.virtualenvs\yushu_book.git-6_6nMzLI\Lib\site-packages\flask_sqlalchemy\extension.py", line 900, in create_all
self._call_for_binds(bind_key, "create_all")
~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\41935\.virtualenvs\yushu_book.git-6_6nMzLI\Lib\site-packages\flask_sqlalchemy\extension.py", line 871, in _call_for_binds
engine = self.engines[key]
^^^^^^^^^^^^
File "C:\Users\41935\.virtualenvs\yushu_book.git-6_6nMzLI\Lib\site-packages\flask_sqlalchemy\extension.py", line 687, in engines
app = current_app._get_current_object() # type: ignore[attr-defined]
File "C:\Users\41935\.virtualenvs\yushu_book.git-6_6nMzLI\Lib\site-packages\werkzeug\local.py", line 519, in _get_current_object
raise RuntimeError(unbound_message) from None
RuntimeError: Working outside of application context.
This typically means that you attempted to use functionality that needed
the current application. To solve this, set up an application context
with app.app_context(). See the documentation for more information.
7.3.2 应用上下文环境
在报错中,发现提到了一个新的名词,上下文环境,在 Flask-SQLAlchemy 中,app.app_context() 的作用是为当前操作绑定一个应用上下文环境,这是 Flask 框架设计中的核心机制——应用上下文。
我们现在将此概念按下不表,做如下修改,发现代码就可以成功运行了
错误写法(无上下文):
def create_app():
app = Flask(__name__)
db.init_app(app)
db.create_all() # ❌ 无上下文,无法获取 app 实例
return app
正确写法(激活上下文):
def create_app():
app = Flask(__name__)
db.init_app(app)
with app.app_context(): # ✅ 显式激活上下文
db.create_all() # 可安全访问 app.config
return app
经过修改,就能够成功的创建book数据表了
7.3.3 ORM与CodeFirst的区别
在开发工程中,CodeFirst可以让我们更专注业务模型的设计,而不是数据库的设计。MVC 中的 M 并不是只有数据,他是个业务模型,他还有操作整个数据的方法,所以设计面试就会提到业务逻辑是需要在MVC的M层定义
有同学会提到ORM也能操作数据库,ORM是对象关系映射,他会关注数据库的增删改查,接下来我们操作数据库就是通过ORM进行的,而CodeFirst关注的是数据怎么创建的,也就是数据表怎么创建,CodeFirst属于ORM的一个分支
