002.数据与flask路由
注:数据由于本地数据库较小,所以数据检索来源第三方网站
# 鱼书基地址
http://talelin.com
# 关键字搜索
http://talelin.com/v2/book/search?q={}&start={}&count={}
# isbn搜索
http://talelin.com/v2/book/isbn/{isbn}
# 豆瓣API
https://api.douban.com/v2/book
1.搜索关键字
由于视图函数是web项目的起始点,所以在代码维护中不建议将视图函数的代码写的繁杂
在书籍搜索中,我们可以搜索关键字或者isbn,我们将搜索关键字或者isbn的判断写在了helper.py模块中
def is_isbn_or_key(word):
'''
获得字符串,判断是否为isbn编码
:param word: 字符串 或者 isbn编码
:return: 判断结果 isbn or key
'''
isbn_or_key = "key"
if len(word) == 13 and word.isdigit():
isbn_or_key = "isbn"
short_word = word.replace('-', '')
if '-' in word and len(short_word) == 10 and short_word.isdigit():
# 首先判断文本中是否包含 - 然后将 - 替换成空格,并且去除空格后看是否为10位,在看是否位纯数字
isbn_or_key = "isbn"
return isbn_or_key
from flask import Flask,make_response # flask提供创建response的对象
from helper import is_isbn_or_key
import config
app = Flask(__name__)
# 读取配置文件
app.config.from_object(config) # 这里倒入的是模块路径
@app.route('/')
def index():
headers = {
'Content-Type': 'text/plain; charset=utf-8',
} # 设置响应头
response = make_response("<html><h1>这是一个html页面</h1></html>",200) # 创建response对象
response.headers = headers # 设置响应头
return response # 返回response对象
@app.route("/book/search/<q>/<page>")
def search(q,page):
'''
视图函数需要2个参数 q(普通关键字、isbn)、page(页面)
:return:
'''
# isbn搜索 isbn13有13个0-9的数字组成 isbn10 有10个0-9的数字组成,含有'-'做补充
isbn_or_key = is_isbn_or_key(q)
return isbn_or_key
if __name__ == "__main__":
app.run(host="0.0.0.0",port=82,debug=app.config["DEBUG"]) # 字典一样使用配置文件
2 使用鱼书API
课程导师在本地部署了一个api供我们使用。
# api最新地址
http://t.talelin.com/v2/book/isbn/9787501524044
# 未找到图书返回值 状态码404
{"msg": "book not found", "code": 2000}
# 找到图书的返回值 状态码200
{
"author": [
"蔡智恒"
],
"binding": "平装",
"category": "小说",
"id": 1780,
"image": "https://img3.doubanio.com/lpic/s1327750.jpg",
"images": {
"large": "https://img3.doubanio.com/lpic/s1327750.jpg"
},
"isbn": "9787501524044",
"pages": "224",
"price": "12.80",
"pubdate": "1999-11-1",
"publisher": "知识出版社",
"subtitle": "",
"summary": "你还没有试过,到大学路的麦当劳,点一杯大可乐,与两份薯条的约会方法吗?那你一定要读目前最抢手的这部网络小说——《第一次的亲密接触》。\\n由于这部小说在网络上一再被转载,使得痞子蔡的知名度像一股热浪在网络上延烧开来,达到无国界之境。作者的电子信箱,每天都收到热情的网友如雪片飞来的信件,痞子蔡与轻舞飞扬已成为网络史上最发烧的网络情人。",
"title": "第一次的亲密接触",
"translator": []
}
我们使用脚本测试一下这个API
import requests
import json # 用于美化JSON输出
isbn = "9787501524044"
# API地址(ISBN固定为9787501524044)
api_url = f"http://t.talelin.com/v2/book/isbn/{isbn}"
# 发送GET请求
response = requests.get(api_url)
# 直接输出原始JSON响应(带格式美化)
try:
raw_json = response.json()
print(f"状态码: {response.status_code}")
print(json.dumps(raw_json, indent=2, ensure_ascii=False)) # 中文显示优化
except requests.exceptions.JSONDecodeError:
print("错误:响应内容不是有效的JSON格式")
3 封装请求和调用
3.1 封装请求过程
封装http_requests.py模块
import requests
# 封装成类方便拓展
class HTTP:
@staticmethod # 静态方法
def get(url,return_json=True):
r = requests.get(url)
# 根据状态码判断是否取到内容
if r.status_code != 200:
# 判断return_json为True返回空字典,为False返回空字符串
return {} if return_json else ""
# 判断是否需要解析json格式
# if return_json: 因为既然已经判断返回了正确的内容,所以直接返回json格式
# 判断return_json为True返回json格式,为False返回text格式
return r.json() if return_json else r.text
3.2 封装调用鱼书API
封装yushu_book.py模块
from http_requests import HTTP
class YushuBook:
isbn_url = 'http://t.talelin.com/v2/book/isbn/{}'
keyword_url = 'http://t.talelin.com/v2/book/search?q={}&count={}&start={}'
@classmethod
def search_by_isbn(cls,isbn):
'''
根据isbn搜索图书
:param isbn:
:return:
'''
url = cls.isbn_url.format(isbn)
result = HTTP.get(url)
return result
@classmethod
def search_by_keyword(cls,keyword,count=15,start=0): #count取15条 start从第0条开始取
url = cls.keyword_url.format(keyword,count,start)
result = HTTP.get(url)
return result
cls能够读取到isbn_url和keyword_url,因为这些属性是定义在类YushuBook上的类属性,而类方法通过cls参数引用类本身,从而可以访问这些类属性。这是Python类和方法设计的一部分,允许类方法直接访问和操作类级别的数据。而实例(self)可以访问类的所有属性。当实例自身没有定义 isbn_url 或 keyword_url 时,Python 开启链式查找,会自动向上查找类的属性。
3.3 使用鱼书API
from flask import Flask,make_response # flask提供创建response的对象
from yushu_book import YushuBook
import config
import helper
import json
app = Flask(__name__)
# 读取配置文件
app.config.from_object(config) # 这样导入是模块路径
@app.route('/')
def index():
headers = {
'Content-Type':'text/html;charset=utf-8',
} # 设置响应头
response = make_response('<html><h1>不好意思哦,主页跑丢了</h1></html>',400)
response.headers = headers
return response
@app.route("/book/search/<q>/")
def search(q,page=1):
'''
视图函数需要四个参数 q(普通关键字、isbn)、page(页面)
:return:
'''
# isbn搜索 isbn13有13个0-9的数字组成 isbn10 有10个0-9的数字组成,含有'-'做补充
isbn_or_key = helper.is_isbn_or_key(q)
if isbn_or_key == 'isbn':
result = YushuBook.search_by_isbn(q)
else:
result = YushuBook.search_by_keyword(q,page)
# 为了保证flask不报错,先将json格式解码成字典进行返回,然后在使用http头告诉浏览器这个实际是json格式
return json.dumps(result),200,{'Content-Type':'application/json'}
if __name__ == '__main__':
app.run(host='0.0.0.0',port=82,debug=app.config["DEBUG"])
为了保证flask不报错,先将json格式解码成字典进行返回,然后在使用http头告诉浏览器这个实际是json格式
return json.dumps(result),200,{'Content-Type':'application/json'}
json是python为我们提供的工具,flask为我们提供了一个更简便的工具
# 在flask中需要单独导入
from flask import jsonify
# 上诉的过程可以使用jsonify自动完成
return jsonify(result)
注意:API的难点在于路由设计上
4 将视图函数拆分到单独的文件
不推荐将视图函数都放在同一个文件中,首先会导致单个文件过长不利于维护,其次不同的业务模型应该放到不同的文件中去,以利于功能分区
例如:我们现在正在编辑的是搜索书籍的功能,他作为书籍相关的业务模型,应该在书籍类目中独立一个视图函数,后续编写用户视图函数,那么登陆、注册等用户功能应该放到用户的视图函数中!
注意:就算要把视图函数放到一起,也不应该放到入口文件中,入口文件会做很多初始化工作
4.1 改造视图函数
在根目录中创建一个目录app,在app目录下新建目录叫做web,web下创建book.py文件专门存放book业务模型的视图函数
import helper
from flask import jsonify
from yushu_book import YushuBook
# 为了确保app.route能够准确执行,所以我们把启动文件导入到book.py中使用
from main import app # 错误示范
@app.route("/book/search/<q>/")
def search(q,page=1):
'''
视图函数需要四个参数 q(普通关键字、isbn)、page(页面)
:return:
'''
# isbn搜索 isbn13有13个0-9的数字组成 isbn10 有10个0-9的数字组成,含有'-'做补充
isbn_or_key = helper.is_isbn_or_key(q)
if isbn_or_key == 'isbn':
result = YushuBook.search_by_isbn(q)
else:
result = YushuBook.search_by_keyword(q,page)
return jsonify(result)
from flask import Flask
import config
app = Flask(__name__)
app.config.from_object(config)
from app.web import book # 错误示范
if __name__ == '__main__':
app.run(host='0.0.0.0',port=82,debug=app.config["DEBUG"])
在这里会有一个问题?这种引入方式是否能够成功定义路由?
4.2 endpoint 的定义与作用
我们做一个简单的小测试,使用pycharm采用断点查看路由的定义过程
from flask import Flask, jsonify
import config
import helper
from yushu_book import YushuBook
app = Flask(__name__)
# 读取配置文件
app.config.from_object(config) # 这样导入是模块路径
@app.route("/book/search/<q>/", endpoint='search') # 在此同样支持endpoint
def search(q,page=1):
#使用函数定义路由 # url是url路径,view_func是视图函数,endpoint是视图函数的名字,可以自定义,默认为函数名字
# app.add_url_rule("url",view_func=search, endpoint='search') # 这里只是说明可以这么定义
isbn_or_key = helper.is_isbn_or_key(q)
if isbn_or_key == 'isbn':
result = YushuBook.search_by_isbn(q)
else:
result = YushuBook.search_by_keyword(q,page)
return jsonify(result)
if __name__ == '__main__':
app.run(host='0.0.0.0',port=82) # 注意为了避免冲突,在此需要关闭flask的debug功能
单击ctrl+鼠标点击@app.route,条转到装饰器内部,打上断点
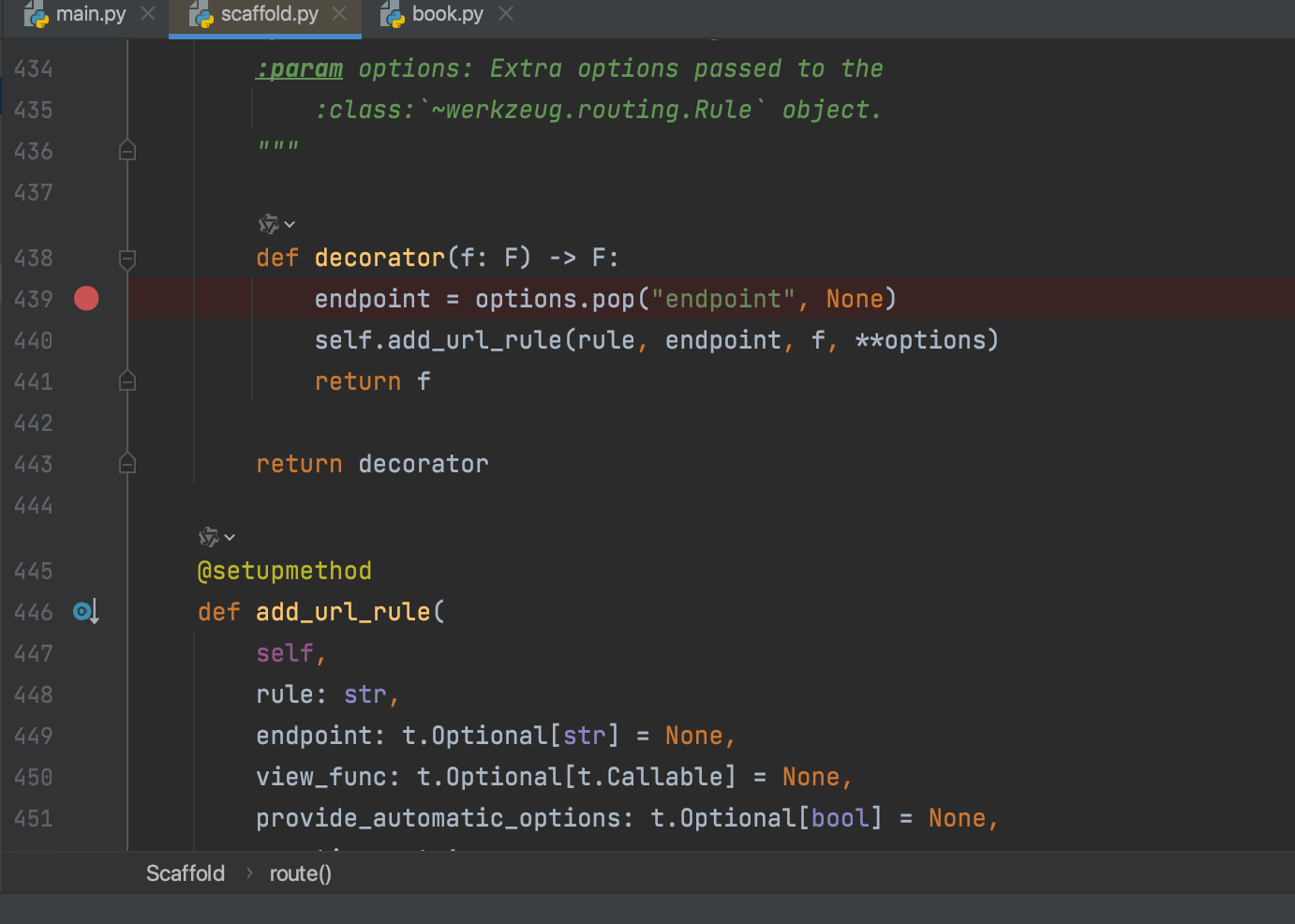
我们可以看到,route装饰器的本质是调用了self.add_url_rule(rule, endpoint, f, **options)方法,首先在装饰器内部,他会尝试去获取endpoint,由于我们并没有去传递这个参数。
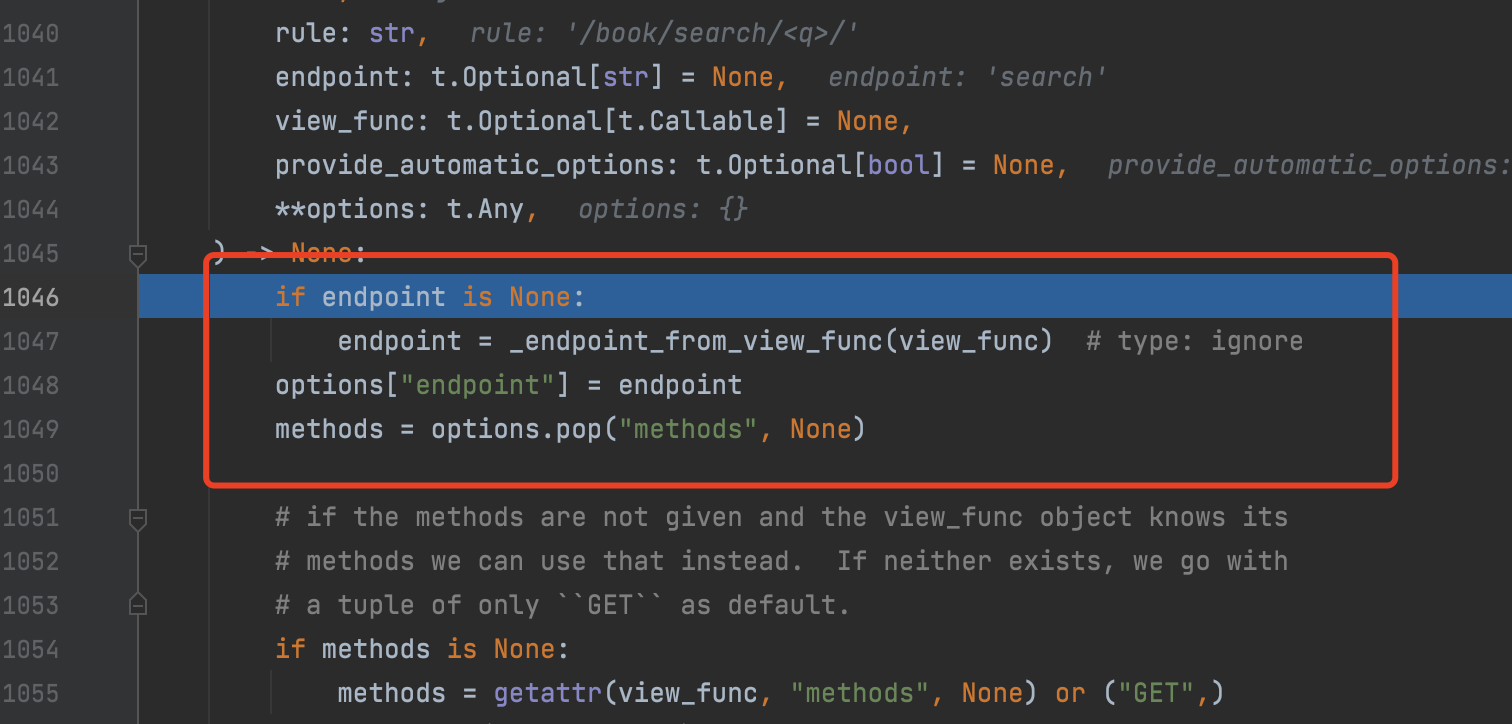
我们能够看到它判断endpoint函数为空,就会获取view_func函数名称作为endpoint值
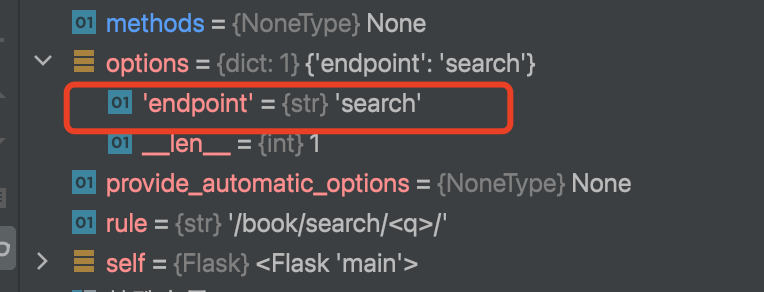
然后会生成一个options字典,让endpoint值作为key指向目标函数名
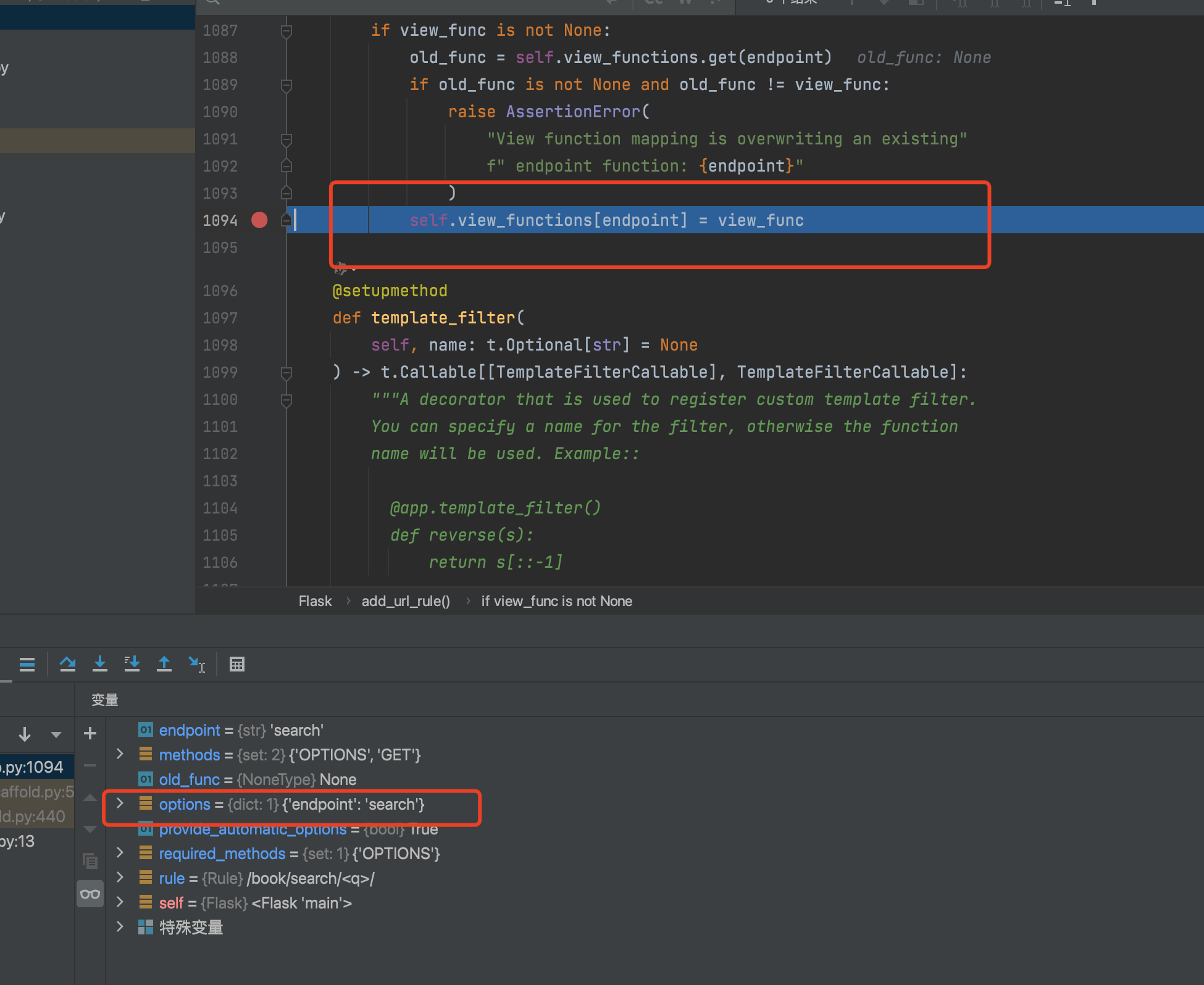
最后看定义完成后的函数结果,url_map中包含了url路径指向了endpoint

在view_functions也指向了endpoint

经过源码分析,我们发现在flask中,路由的定义并非是直接让URL指向目标函数,而是经过了endpoint这个中间层

实际上endpoint 是Flask中用于标识路由的唯一名称。每个路由都有一个对应的endpoint,它在生成URL时用于指向特定的视图函数。endpoint 的主要作用是提供一种抽象方式,使得URL生成独立于具体的路由路径。
当请求到达时,Flask通过 url_map(存储所有URL规则的路由映射表)进行匹配,每个URL规则关联一个 endpoint(逻辑标识符,如默认使用视图函数名),匹配成功时,解析出对应的 endpoint 和参数(如动态路由中的<id>),获得 endpoint 后,Flask会通过 view_functions(存储端点与函数的映射字典)使用endpoint作为key取出对应的视图函数,若未找到会抛出 AssertionError(常见于未注册的端点)
唯一性约束:整个应用中
endpoint 必须全局唯一(尤其在蓝图中需注意命名冲突)底层实现:
url_for() 反向构建URL时也依赖endpoint 作为中间层
==补充说明======
web/yushu_book.py
from http_requests import HTTP
from flask import current_app
class YushuBook:
isbn_url = 'http://t.talelin.com/v2/book/isbn/{}'
keyword_url = 'http://t.talelin.com/v2/book/search?q={}&count={}&start={}'
@classmethod
def search_by_isbn(cls,isbn):
'''
根据isbn搜索图书
:param isbn:
:return:
'''
url = cls.isbn_url.format(isbn)
result = HTTP.get(url)
return result
@classmethod
def search_by_keyword(cls,keyword,page=1):
url = cls.keyword_url.format(keyword,current_app.config['PER_PAGE'],cls.calculate_start(page))
result = HTTP.get(url)
return result
# 类的封装不在于代码的长度,而是根据功能进行封装
# 获取json条目的起始位置
@staticmethod
def calculate_start(page):
return (page-1) * current_app.config['PER_PAGE']
4.2.1 默认endpoint 的生成
如果没有指定endpoint,Flask会默认使用视图函数的名称作为endpoint。例如,定义如下路由:
@app.route('/hello')
def hello():
return 'Hello, World!'
默认情况下,该路由的endpoint为'hello',即视图函数的名称。
4.2.2 endpoint 的用途
URL生成:使用
url_for()函数时,需要传入endpoint名称来生成对应的URL。例如:
url_for('hello') # 生成 '/hello'
蓝图管理:在使用蓝图时,
endpoint帮助组织和管理不同模块的路由,避免命名冲突。自定义路由:允许开发者为路由指定唯一的
endpoint,以便更灵活地生成URL。
4.2.3 endpoint 与路由的关系
一对一关系:每个路由对应一个唯一的
endpoint。即使多个路由指向同一个视图函数,每个路由都有自己的endpoint。显式指定:可以通过在
@app.route装饰器中指定endpoint参数来覆盖默认名称。例如:
@app.route('/hello', endpoint='greeting')
def hello():
return 'Hello, World!'
此时,`url_for('greeting')`将生成`'/hello'`。
4.2.4 endpoint 在蓝图中的作用
在蓝图中,endpoint通常与蓝图名称组合使用,以避免不同蓝图之间的命名冲突。例如:
from flask import Blueprint
bp = Blueprint('api', __name__)
@bp.route('/hello', endpoint='hello')
def hello():
return 'Hello, World!'
当注册蓝图时,完整的endpoint将是'api.hello',生成URL时使用:
url_for('api.hello') # 生成 '/hello'
如果flask的路由想要注册成功,那么她需要url_map中包含了url路径指向了endpoint,并且在view_functions也指向了endpoint,由endpoint作为承上启下的中间人进行路由搜索
4.3 循环引入流程分析
回到前文3.4.1 改造视图函数提出的问题,import引入方式是否能够成功定义路由?
使用断点调试以下代码:
from flask import Flask
import config
app = Flask(__name__)
# 读取配置文件
app.config.from_object(config) # 设置断点
from app.web import book
if __name__ == '__main__':
app.run(host='0.0.0.0',port=82)
from main import app # 在此导入app
import helper
from yushu_book import YushuBook
from flask import jsonify
@app.route("/book/search/<q>/", endpoint='search')
def search(q,page=1):
isbn_or_key = helper.is_isbn_or_key(q)
if isbn_or_key == 'isbn':
result = YushuBook.search_by_isbn(q)
else:
result = YushuBook.search_by_keyword(q,page)
return jsonify(result)
经过断点调试我们可以发现,在main.py中,app被初始化后,来到了from app.web import book加载book.py内容,但发现跳转到book.py页面后,会因为from main import app,又再次回到main.py页面,根本不会执行到@app.route("/book/search/<q>/", endpoint='search')定义路由,再度来到from app.web import book却会因为只加载一次的缘由,而if name == '__main__':中的代码,则会因为该模块是由book.py调用生成,导致不会执行,程序又回回到book.py执行后续的加载和代码
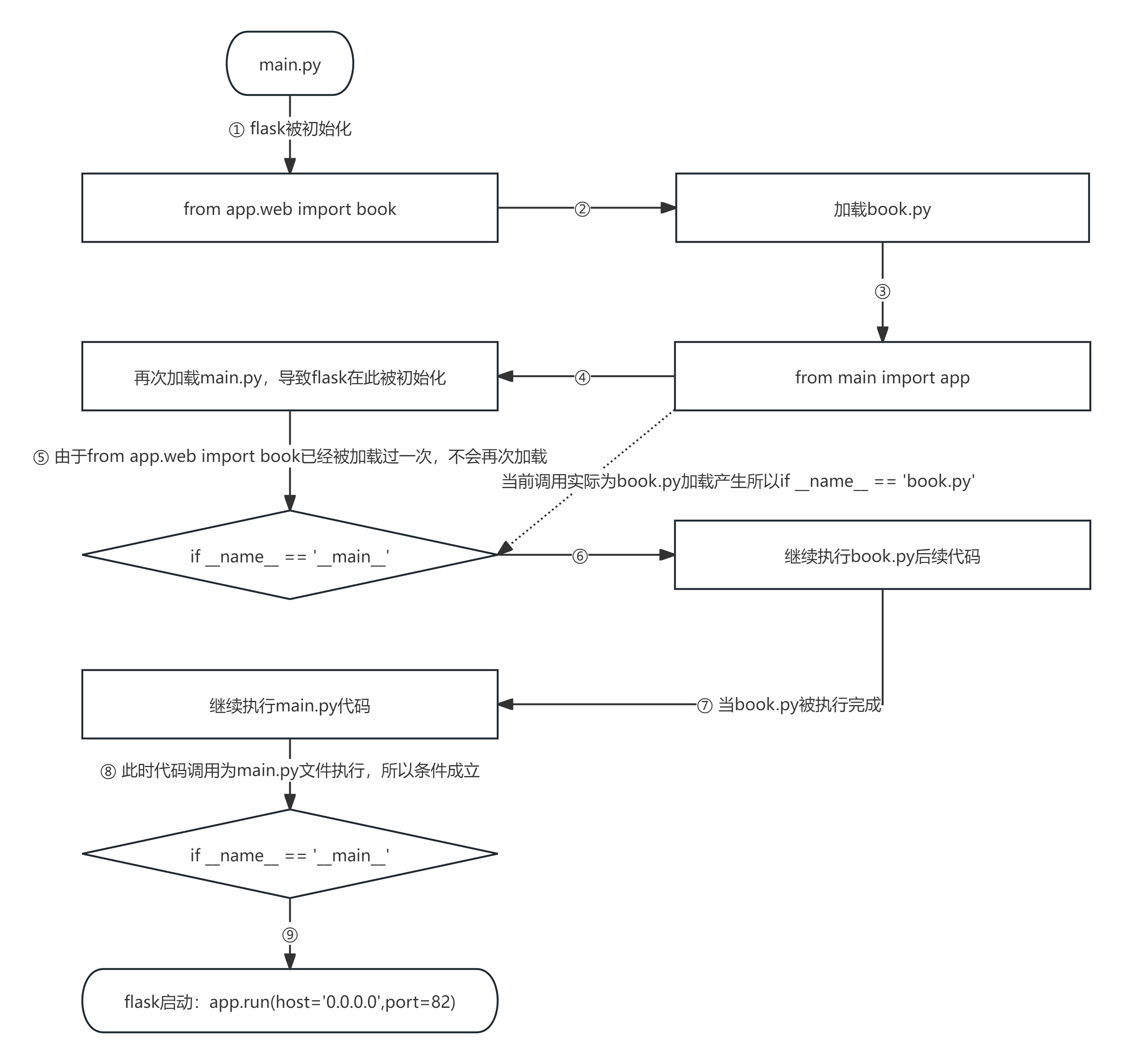
通过流程图展现,我们能够发现app = Flask(__name__)分别在main.py发起的流程和book.py发起的流程中,被初始化了两次,而@app.route("/book/search/<q>/", endpoint='search')把路由定义在了book.py流程中,启动flask的却是main.py流程
注释:可以在
main.py中app = Flask(__name__)和if name == '__main__':以及book.py中的@app.route("/book/search/<q>/", endpoint='search')位置添加id(app)查看app的id,以证明他们是不同的app
这也就解释了为什么通过此种方式无法成功注册路由的原因。
