Python开发-020_函数嵌套和装饰器
1 函数嵌套
python是以函数为作用域,在作用域中定义的相关数据只能被当前作用域或子作用域使用
NAME = 'kinght'
age = 22
def func():
age = 23
print(NAME) # kinght
print(age) # 23
func()
print(age) # 22
1.1 函数在作用域中
函数也是定义在作用域中的数据,在执行函数时候,也同样遵循优先在自己作用域中寻找,没有则向上一接作用域寻找的原则
# 1. 在全局作用域定义了函数func
def func():
print("你好")
# 2. 在全局作用域找到func函数并执行。
func()
# 3.在全局作用域定义了execute函数
def execute():
print("开始")
# 优先在当前函数作用域找func函数,没有则向上级作用域中寻找。
func()
print("结束")
# 4.在全局作用域执行execute函数
execute()
同样也要遵循python至上而下的运行原则
def func():
print("你好")
func() # 你好
def execute():
print("开始")
func()
print("结束")
def func():
print(666) # 这里直接将func的内存空间给覆盖了
func() # 666
# 这里是覆盖之后再执行的execute函数
execute() # 开始 666 结束
1.2 函数定义的位置
上述示例中的函数均定义在全局作用域,其实函数也可以定义在局部作用域,这样函数被局部作用域和其子作用于中调用(函数的嵌套)
def func():
print("沙河高晓松")
def handler():
print("昌平吴彦祖")
def inner():
print("朝阳大妈")
inner()
func()
print("海淀网友")
handler()
为什么要这么嵌套定义?把函数都定义在全局不好吗?
大多数情况下我们都会将函数定义在全局,不会嵌套着定义函数。不过,当我们定义一个函数去实现某功能,想要将内部功能拆分成N个函数,又担心这个N个函数放在全局会与其他函数名冲突时(尤其多人协同开发)可以选择使用函数的嵌套
"""
生成图片验证码的示例代码,需要提前安装pillow模块(Python中操作图片中一个第三方模块)
pip3 install pillow
字体选择在下方修改注释
"""
import random
from PIL import Image, ImageDraw, ImageFont
def create_image_code(img_file_path, text=None, size=(120, 30), mode="RGB", bg_color=(255, 255, 255)):
""" 生成一个图片验证码 """
_letter_cases = "abcdefghjkmnpqrstuvwxy" # 小写字母,去除可能干扰的i,l,o,z
_upper_cases = _letter_cases.upper() # 大写字母
_numbers = ''.join(map(str, range(3, 10))) # 数字
chars = ''.join((_letter_cases, _upper_cases, _numbers))
width, height = size # 宽高
# 创建图形
img = Image.new(mode, size, bg_color)
draw = ImageDraw.Draw(img) # 创建画笔
def get_chars():
"""生成给定长度的字符串,返回列表格式"""
return random.sample(chars, 4)
def create_lines():
"""绘制干扰线"""
line_num = random.randint(*(1, 2)) # 干扰线条数
for i in range(line_num):
# 起始点
begin = (random.randint(0, size[0]), random.randint(0, size[1]))
# 结束点
end = (random.randint(0, size[0]), random.randint(0, size[1]))
draw.line([begin, end], fill=(0, 0, 0))
def create_points():
"""绘制干扰点"""
chance = min(100, max(0, int(2))) # 大小限制在[0, 100]
for w in range(width):
for h in range(height):
tmp = random.randint(0, 100)
if tmp > 100 - chance:
draw.point((w, h), fill=(0, 0, 0))
def create_code():
"""绘制验证码字符"""
if text:
code_string = text
else:
char_list = get_chars()
code_string = ''.join(char_list) # 每个字符前后以空格隔开
# Win系统字体
# font = ImageFont.truetype(r"C:\Windows\Fonts\SEGOEPR.TTF", size=24)
# Mac系统字体
font = ImageFont.truetype("/System/Library/Fonts/SFNSRounded.ttf", size=24)
# 项目字体文件
# font = ImageFont.truetype("MSYH.TTC", size=15)
draw.text([0, 0], code_string, "red", font=font)
return code_string
create_lines()
create_points()
code = create_code()
# 将图片写入到文件
with open(img_file_path, mode='wb') as img_object:
img.save(img_object)
return code
code = create_image_code("a2.png")
print(code)
1.3 嵌套引发的作用域问题
name = "kinght"
def run():
name = "aym"
def inner():
print(name)
inner()
run()
对执行过程进行一下分析,首先在程序由上而下进行执行的过程中,会创建两个全局变量name和run,然后执行函数run(),执行函数内部会生成一个调用栈,也就是一个作用域
在run函数的作用域里面,有两个变量name和inner,然后在执行inner()函数,里面又会生成一个调用栈道,里面放着代码print(name),但是name函数在inner的作用域里面没有,就向上一级查找,在run函数中找到了,所以输出aym
name = "武沛齐"
def run():
name = "alex"
def inner():
print(name)
return inner
v1 = run()
v1() # alex
v2 = run()
v2() # alex
对执行过程进行分析,首先全局作用域生成name run两个变量,在生成v1的时候发现需要执行run()并获得返回值,run函数执行这一层生成变量name inner,将inner的内存地址返还交给了v1,v1()执行进入了函数,内部代码print(name),本层没有name变量,就向上一层进行寻找,而inner作用域的上一层是run作用域,所以寻找到值为name=alex,v2变量与v1同理,只不过由于又执行了v2=run(),所以又创建了一个run作用域,在下图简略未画出
tips:函数执行完成后,本应该将内存空间销毁,但由于inner的内存空间交给了v1 v2,引用计数器没有归0,所以保留,后续会在垃圾回收章节进行详细介绍
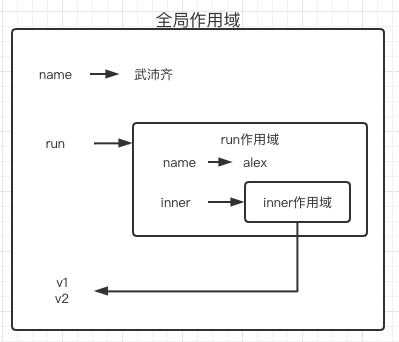
三句话搞定作用域:
- 优先在自己的作用域找,自己没有就去上级作用域。
- 在作用域中寻找值时,要确保此次此刻值是什么。
- 分析函数的执行,并确定函数
作用域链。(函数嵌套)
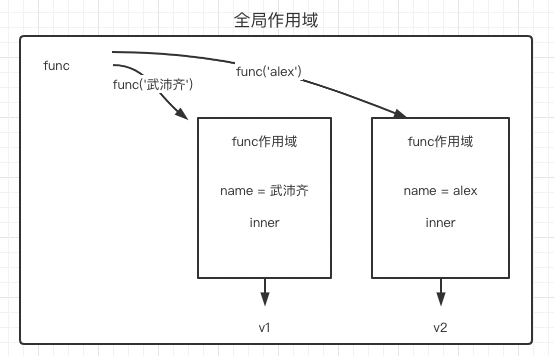
def func(name):
def inner():
print(name)
return 'luffy'
return inner
v1 = func('武沛齐')() # 武沛齐
print(v1) # luffy
v2 = func('alex')() # alex
print(v2) # luffy
全局作用域创建变量func,v1需要执行func('武沛齐')获取赋值,在func作用域内创建了name=武沛齐 inner两个变量,return inner将inner的内存地址交给了v1 = func('武沛齐'),变成了v1=inner(),执行来到inner作用域,print(name)找不到name值,就向上层查找,找到了func作用域的name=武沛齐获得了输出,然后返回了luffy给v1,所以print(v1)输出luffy,v2同理省略
1.3.1 嵌套函数多次运行会生成多个作用域
def func(name):
def inner():
print(name)
return 'luffy'
return inner
v1 = func('武沛齐')
v2 = func('alex')
v1()
v2()
其实这一点前几个实例同样存在,只是问题不明显所以没有专门叙述
程序运行,全局作用域生成func变量,而在生成v1的时候需要func('武沛齐') 的返回值,执行函数func(),在func作用域中,有生成了inner变量,并且return inner,所以v1 = inner
同样的情况遇到v2 = func('alex'),在生成v2的时候需要func('alex') 的返回值,执行函数func(),在func作用域中,有生成了inner变量,并且return inner,所以v2 = inner
在他们两完成后,执行v1() v2(),结果却不相同
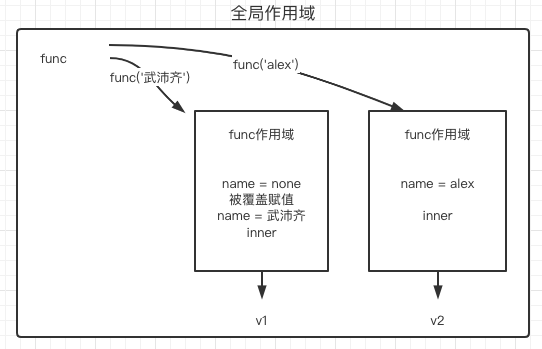
def func(name=None):
if not name:
name= '武沛齐'
def inner():
print(name)
return 'root'
return inner
v1 = func()() # 武沛齐
v2 = func('alex')()
print(v1,v2)
程序运行,全局作用域生成func变量,在生成v1的时候需要func()()的返回值,那么进入func函数,创建func作用域,由于没有实参,在func作用域形参默认值生成name=None变量,if not name成立,故name= '武沛齐'。func作用域同时还生成了一个inner变量,并且return inner,即v1 = func()()转变为v1=inner(),来到inner作用域,print(name)需要找到name值进行输出,而inner作用域中没有name值,在其上层作用域func中找到name= '武沛齐'得到输出,返回root
生成v2 = func('alex')(),func作用域生成了name=alex inner变量,由于name=alex为True,故不执行判断内语句,直接执行返回return inner,即v2 = inner(),来到inner作用域,发现语句需要输出name,同级没有,其上一级作用域name = alex,故输出alex,返回root
最后执行print(v1,v2),得到root root
2 闭包
闭包是函数嵌套创建出的特殊情况,简而言之就是将数据封装到一个包(区域/作用域)里,使用时再去调用
'闭':该函数是内嵌函数
'包':该函数包含对外层函数(不是全局函数)作用域名字的引用
2.1 闭包的目的
2.1.1 防止数据污染全局
demo = 'aym'
def func():
demo = 'kinght'
def func1():
print(demo) # kinght
def func2():
pass
func1()
func2()
func()
print(demo) # aym
把数据封装起来,不会污染到全局变量去
2.1.2 把功能数据封装到一个包里
# 爬取一个html页面
import requests
# 方案一:传参 - 通过参数方式为函数体传值
def get(url):
response = requests.get(url)
print(response.text)
get('https://kinghtxg.com')
# 方案二:闭包 - 通过闭包的方式为函数体传值
def get(url):
def get_url():
response = requests.get(url)
print(response.text)
return get_url
# 把数据封装起来为专门爬取百度和专门爬取博客的
baidu = get('https://www.baidu.com')
baidu()
blog = get('https://kinghtxg.com')
blog()
2.2 闭包演示
2.2.1多线程下载视频案例->直观案例
import requests
from concurrent.futures.thread import ThreadPoolExecutor # 多线程的包
POOL = ThreadPoolExecutor(10) # 申请10个线程
video_dict = [
("东北F4模仿秀.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"),
("卡特扣篮.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34q1g"),
("罗斯mvp.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg")
]
def download_mp4(movie_name, url):
def task():
res = requests.get(
url=url,
headers={
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 FS"
}
)
with open(movie_name,mode='wb') as file_object:
file_object.write(res.content)
return task
task1 = download_mp4(video_dict[0][0],video_dict[0][1])
task2 = download_mp4(video_dict[1][0],video_dict[1][1])
task3 = download_mp4(video_dict[2][0],video_dict[2][1])
# POOL.submit使用现场调用函数 -> 函数名不同调用多个函数
POOL.submit(task1)
POOL.submit(task2)
POOL.submit(task3)
2.2.1多线程下载视频案例->实际开发案例
import requests
from concurrent.futures.thread import ThreadPoolExecutor # 多线程的包
POOL = ThreadPoolExecutor(10) # 申请10线程
video_dict = [
("东北F4模仿秀.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"),
("卡特扣篮.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34q1g"),
("罗斯mvp.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg")
]
def download_video(url):
res = requests.get(
url=url,
headers={
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 FS"
}
)
return res.content
# 修改之前的用法 -> 没有办法获取文件名
# def done(arg):
# with open("xx.mp4",mode='wb') as file_object:
# file_object.write(arg)
# 修改之后的用法
def outer(filename):
def done(arg):
content = arg.result() # arg.result()获取的就是res.content
with open(filename,mode='wb') as file_object:
file_object.write(content)
return done
for item in video_dict:
future = POOL.submit(download_video,url=item[1]) # 上诉函数运行结果递交给future函数(并不是递交的res.content)
# 修改之前的用法
# future.add_done_callback(done) # 这里是将上诉接收到的结果,再次调用done函数,并递交给arg
# 所以我们应该这么用 相当于 outer(item[0]) = done(arg) , 并且封了一个filename = item[0] 的变量值在其中
future.add_done_callback(outer(item[0]))
3 装饰器
'器'指的是工具/器具
'装饰'指的是为其他事物添加额外的东西点缀
装饰器指的是定义一个函数(或者类),该函数是用来装饰其他函数的(为其他函数添加额外的功能),准确的说装饰器的作用就是在不修改被装饰对象源代码和调用方式的前提下为被装饰对象添加额外的功能
3.1 开放封闭原则
软件的设计应该遵循开放封闭原则
开放:对拓展功能是开放的
封闭:对修改源代码是封闭的
对拓展功能开放,意味着有新的需求或变化时,可以对现有代码进行扩展,以适应新的情况。对修改封闭,意味着函数/对象一旦设计完成,就可以独立完成其工作,而不要对其进行修改
软件包含的所有功能的源代码以及调用方式,都应该避免修改,否则一旦改错,则极有可能产生连锁反应,最终导致程序崩溃,而对于上线后的软件,新需求或者变化又层出不穷,我们必须为程序提供扩展的可能性,这就用到了装饰器
3.2 装饰器的实现流程
为了跟方便的理解装饰器的含义,我们需要完成一个小的功能
import time
def index(name,age):
time.sleep(3) # 暂停3秒
print('name:%s,age:%s' %(name,age))
index('kinght','20')
需求1:为index添加统计运行时间的功能
import time
def index(name,age):
# 添加起始时间记录
start = time.time() # time.time 从uninx元年(1970年1月1日)到现在的秒
time.sleep(3) # 暂停3秒
print('name:%s,age:%s' %(name,age))
# 记录运行结束的时间
stop = time.time()
# 输出运行时间 结束时间减去起始时间 = 运行时间
print(stop - start)
index('kinght','20')
需求2:在不修改index函数源代码以及调用方式的情况下为其添加统计运行时间的功能
import time
def index():
time.sleep(3) # 暂停3秒
print('abcdefg')
def outer(origin):
def inner():
start = time.time()
origin()
stop = time.time()
print(stop - start)
return inner
index = outer(index)
index()
案例讲解:
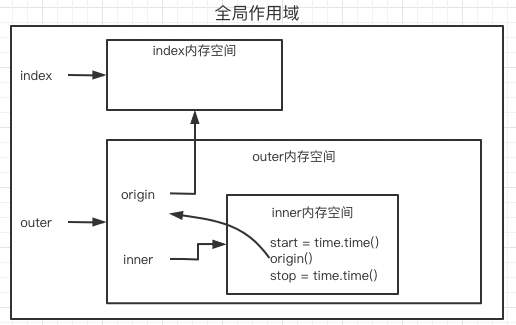
简单介绍:
1.index = outer(index),首先执行outer(index),在outer作用域中,有两个变量,一个是指向全局作用域中的origin = index,而另一个则是则是inner,在inner未执行的时候,就被return inner,所以可以理解新的index指向的是inner
2.index()执行的就是inner中的代码,而inner中有执行origin()函数,之前我们已知origin指向的是原index的内存地址,所以执行的实际代码也就变成了
start = time.time()
time.sleep(3) # 暂停3秒
print('abcdefg')
stop = time.time()
需求3:index本身拥有参数
修改需求,index不再是原来的样子,而是
def index(name,age):
time.sleep(3) # 暂停3秒
print('name:%s,age:%s' %(name,age))
index('kinght','20')
同样在代码上面添加计算运行秒数的功能
import time
def index(name,age):
time.sleep(3) # 暂停3秒
print('name:%s,age:%s' %(name,age))
def outer(func):
def inner(*args,**kwargs): # 接受参数
start = time.time()
# 如果有被装饰函数有返回值,可以通过res接受后进行返回
res = func(*args,**kwargs) # 将接受到的参数自动打散,作为参数调用原来的index函数
stop = time.time()
print(stop - start)
return res # 返回被装饰函数的返回值
return inner
index = outer(index)
index('kinght','23')
将inner添加可变形参,在inner调用原始函数的时候,传递给原始函数即可完成让index拥有参数
3.3 装饰器的优势所在
现在发现了一个问题,使用了装饰器之后会比使用装饰器之前的代码量更多了!那么装饰器的优势在哪里呢?
import time
def index(x,y,z):
time.sleep(2)
print('index x=%s y=%s z=%s'%(x,y,z))
return 'index'
def home(name):
time.sleep(5)
print('welcome %s to home page'%name)
index(1,2,3)
home('kinght')
需求:给index和home添加统计运行时间的功能
import time
def index(x,y,z): # index函数源代码没有改变
time.sleep(2)
print('index x=%s y=%s z=%s'%(x,y,z))
return 'index'
def home(name):
time.sleep(5)
print('welcome %s to home page'%name)
def timmer(func):
'''计算运行时长的装饰器'''
def wrapper(*args,**kwargs): # 可以接受任意参数
start = time.time() # time.time 从uninx元年(1970年1月1日)到现在的秒
res = func(*args,**kwargs) # 传递函数的参数,并接受返回值
stop = time.time()
print(stop - start)
return res # 返回被装饰函数的返回值
return wrapper
index = timmer(index) # timmer(待测量运行时长的函数名)
res = index(1,2,3) # 使用者调用方式没有改变,但增加了程序运行计算时长的功能
print(res)
print(index.__name__) # 返回真实的函数名
home = timmer(home) # 也可以装饰其他对象
home('kinght')
我们就可以不一个一个函数的进行添加
3.4 装饰器偷梁换柱的要求
index的参数什么样子,装饰器函数的参数就应该什么样子
index的返回值什么样子,装饰器函数的返回值就应该什么样子
index的属性什么样子,装饰器函数的属性就应该什么样子(下文伪装装饰器实现)
3.5 语法糖
每次使用index = timmer(index)还是麻烦,python设置了一个建议的设置叫做语法糖
import time
def outer(func):
def inner(*args,**kwargs):
start = time.time()
res = func(*args,**kwargs)
stop = time.time()
print(stop - start)
return res
return inner
@outer # -> 这个就是语法糖
# 需要注意,由于python是从上至下逐行解释,所以使用语法糖的函数需要在装饰器函数下方
def index(name,age):
time.sleep(3)
print('name:%s,age:%s' %(name,age))
index('kinght','23')
语法糖的作用就是装饰器赋值过程的简写
@装饰器名称
被装饰函数名 = 装饰器名称(被装饰函数名)
3.6 装饰器的叠加
装饰器是为了给函数添加功能,但功能有时候并不一定只添加一次
# 为了区分进行标识
def deco1(func1):
def wrapper1(*args,**kwargs):
print("deco1.wrapper1.func1运行前")
res1 = func1(*args,**kwargs)
print("deco1.wrapper1.func1运行后")
return res1
return wrapper1
def deco2(func2):
def wrapper2(*args,**kwargs):
print("deco2.wrapper2.func2运行前")
res2 = func2(*args,**kwargs)
print("deco2.wrapper2.func2运行后")
return res2
return wrapper2
def deco3(x):
def outter3(func3):
def wrapper3(*args,**kwargs):
print("outter3.wrapper3.func3运行前")
res3 = func3(*args,**kwargs)
print("outter3.wrapper3.func3运行后")
return res3
return wrapper3
return outter3
# 加载顺序自下而上
@deco1 # --> index=deco1(wrapper2的内存地址) ==> index = wrapper1的内存地址
@deco2 # --> index=deco2(wrapper3的内存地址) ==> index = wrapper2的内存地址
@deco3(111) # --> index=outter3(被装饰对象index的内存地址) ==> index = wrapper3的内存地址
def index(x,y):
print('from index %s:%s' %(x,y))
print(index) # 内存地址是wrapper1 <function deco1.<locals>.wrapper1 at 0x0000016EC009ADC0>
# 执行顺序至上而下
# 首先运行deco1,但是执行到func1调用的时候,由于加载,所以知道有deco1调用的是deco2的return,所以会跳转到deco2
# 运行deco2的func2调用,由于加载,所以知道有deco2调用的是deco3的return,所以会跳转到deco3,然后deco3的func来自于index,有调用index
index(1,2)
'''
运行结果:
<function deco1.<locals>.wrapper1 at 0x000001DF92FC1160>
deco1.wrapper1.func1运行前
deco2.wrapper2.func2运行前
outter3.wrapper3.func3运行前
from index 1:2
outter3.wrapper3.func3运行后
deco2.wrapper2.func2运行后
deco1.wrapper1.func1运行后
'''
3.7 无参装饰器模版
装饰其他函数,为其他函数添加功能的函数被称为装饰器,无参装饰器有一个大概统一的格式:
# 装饰器
def outer(origin):
def inner(*args, **kwargs):
# 执行前
res = origin(*args, **kwargs) # 调用原来的func函数
# 执行后
return res
return inner
@outer
def func():
pass
func()
3.8 伪应用场景
此场景需要很多的后置知识,现在还无法搞定,只是基于装饰器提供一个思路
在以后编写一个网站时,如果项目共有100个页面,其中99个是需要登录成功之后才有权限访问,就可以基于装饰器来实现
pip3 install flask
基于第三方模块Flask(框架)快速写一个网站:
from flask import Flask
app = Flask(__name__)
def index():
return "首页"
def info():
return "用户中心"
def order():
return "订单中心"
def login():
return "登录页面"
app.add_url_rule("/index/", view_func=index)
app.add_url_rule("/info/", view_func=info)
app.add_url_rule("/login/", view_func=login)
app.run()
基于装饰器实现的伪代码:
from flask import Flask
app = Flask(__name__)
def auth(func):
def inner(*args, **kwargs):
# 在此处,判断如果用户是否已经登录,已登录则继续往下,未登录则自动跳转到登录页面。
return func(*args, **kwargs)
return inner
@auth
def index():
return "首页"
@auth
def info():
return "用户中心"
@auth
def order():
return "订单中心"
def login():
return "登录页面"
app.add_url_rule("/index/", view_func=index, endpoint='index')
app.add_url_rule("/info/", view_func=info, endpoint='info')
app.add_url_rule("/order/", view_func=order, endpoint='order')
app.add_url_rule("/login/", view_func=login, endpoint='login')
app.run()
3.9 functools
你会发现装饰器实际上就是将原函数更改为其他的函数,然后再此函数中再去调用原函数
# 函数功能性补充
def handler():
'''test123'''
pass
handler()
print(handler.__name__) # 查看被执行函数的名字 handler
print(handler.__doc__) # 查看函数的备注 test123
如果有装饰器的情况下,打印的就是装饰器中被执行函数的名字
def auth(func):
def inner(*args, **kwargs):
return func(*args, **kwargs)
return inner
@auth
def handler():
pass
handler()
print(handler.__name__) # inner
所以我们需要使用functools
import functools # 需要导入
def auth(func):
@functools.wraps(func) # 把原函数作为参数
def inner(*args, **kwargs):
'''321'''
return func(*args, **kwargs)
return inner
@auth
def handler():
'''123'''
pass
handler()
print(handler.__name__) # handler
print(handler.__doc__) # 123
其实,一般情况下大家不用functools也可以实现装饰器的基本功能,但后期在项目开发时,不加functools会出错(内部会读取__name__,且__name__重名的话就报错),所以在此大家就要规范起来自己的写法
4 有参装饰器
无参装饰器的形成是因为要满足偷梁换柱的要求,所以要让wrapper和被装饰对象保持一致,所以在外面套了一层,而有参装饰器又是在无参函数的外面套了一层,这次是因为语法糖不支持
# 错误演示
def outter(func,x): # 假设需要传入两个值语法糖就会报错了
# func = 函数内存地址
def wrapper(*args,**kwargs):
res = func(*args,**kwargs)
return res
return wrapper()
@outter # outter(index) 需要两个参数,但语法糖只传入了一个参数
def index(x,y):
print(x,y)
如果说遇到wrapper内还需要参数,我们就只能再往外套一层
4.1 有参装饰器的实现流程
这是对index函数写登陆验证的装饰器
user
kinght:admin
admin:123
验证器.py
def auth(func):
def wrapper(*args,**kwargs):
name = input("your name>>>:").strip()
passwd = input("your passwd>>>:")
# 基于文本文件user的验证方式
with open('user',mode='rt',encoding='utf-8') as userfile:
for user in userfile:
username,password = user.strip().split(":")
if name == username and passwd == password:
res = func(*args,**kwargs)
return res
else:
print('your username or password error')
return wrapper
@auth
def index(x,y):
print('index -> %s:%s' %(x,y))
index(1,2)
但是现在有个问题,目前的验证装饰器只能适用于文本文件user,而假如需要使用到其他的函数中,其他函数需要使用例如数据库例如LDAP进行验证,这个装饰器的功能就被局限住了
由于还没有学到数据库和LDAP,为了让代码更加直观,所以将从文件中去数据的方式进行文字描述,不写具体代码了
def auth(db_type):
def deco(func):
def wrapper(*args,**kwargs):
name = input('your name>>>:').strip()
pwd = input('your passwrod>>>:').strip()
if db_type == 'file':
print('基于文本的验证')
with open('user', mode='rt', encoding='utf-8') as userfile:
for user in userfile:
username, password = user.strip().split(":")
if name == username and pwd == password:
res = func(*args,**kwargs)
return res
else:
print('your username or password error')
elif db_type == 'mysql':
print('基于mysql的验证')
elif db_type == 'ldap':
print('基于ldap的验证')
else:
print('不支持该验证方式')
return wrapper
return deco
# deco = auth(db_type='file')
# @deco
@auth(db_type='file')
def index(x,y):
print('index -> %s:%s' %(x,y))
index(1,2)
@auth(db_type='mysql')
def home(x,y):
print('home -> %s:%s' %(x,y))
home(1,2)
@auth(db_type='ldap')
def transfer(x,y):
print('transfer -> %s:%s' %(x,y))
transfer(1,2)
我们简化看一下这个代码
def auth(db_type):
def deco(func):
def wrapper(*args,**kwargs):
return wrapper
return deco
其实就是这么些东西,auth返回deco,deco返回wrapper
@auth(db_type='file')
def index(x,y):
print('index -> %s:%s' %(x,y))
index(1,2)
运行@auth('file')等于index = deco(index) + db_type = 'file'就等于index = wrapper(1,2) + db_type = 'file'
4.2 第三层参数可以多个
装饰器为了参数func而套了两层,还需要参数的时候,为了语法糖套了第三层,但是第三层并没有被限制可以无限套娃,所以装饰器最多三层
def auth(db_type,canshu1,canshu2):
def deco(func):
def wrapper(*args,**kwargs):
return wrapper
return deco
@auth('file',canshu1,canshu2) # 第三层可以无限套娃
def index(x,y):
pass
index(1,2)
4.3 有参装饰器模板
# 总结:有参装饰器的基本模板
def 有参装饰器(x,y,z,....)
def outter(func):
def wrapper(*args,**kwargs):
# 1.调用原函数
# 2.为其增加新功能
res = func(*args,**kwargs)
return res
return wrapper
return outter
@有参装饰器(x,y,z,....)
def index():
print('from index')
index()