Python开发-021_生成器与推导式
1 匿名函数
传统函数定义包括了函数名 + 函数体
def send_email():
pass
# 1. 执行
send_email()
# 2. 当做列表元素
data_list = [send_email, send_email, send_email ]
# 3. 当做参数传递
other_function(send_email)
匿名函数,则是基于lambda表达式实现定义一个可以没有名字的函数,例如:
data_list = [ lambda x:x+100, lambda x:x+110, lambda x:x+120 ]
print( data_list[0] )
如果我们把匿名函数还原成传统函数的模样
# 传统函数
def f1(x):
return x + 100
# 匿名函数
f1 = lambda x:x+100
基于Lambda定义的函数格式为:lambda 参数:函数体
-
匿名函数支持任意参数
lambda x: 函数体 lambda x1,x2: 函数体 lambda *args, **kwargs: 函数体 -
匿名函数只支持函数题为单行的代码
f1 = lambda x:x+100 -
默认将函数体单行代码执行的结果返回
func = lambda x: x + 100 v1 = func(10) print(v1) # 110在编写匿名函数时,由于受限函数体只能写一行,所以匿名函数只能处理非常简单的功能,可以快速并简单的创建函数
2 三元运算
为了拓展lambda功能,这里介绍一个和函数没有关系的知识点三元运算
简单的条件运算,可以基于三元运算来实现
# 基础版本
num = input("请写入内容")
if "苍老师" in num:
data = "臭不要脸"
else:
data = "正经人"
print(data)
# 三元运算版本
num = input("请写入内容")
data = "臭不要脸" if "苍老师" in num else "正经人"
# 结果 = 条件成立时结果 if 判断条件 else 条件不成立结果
三元运算结合lambda就可以处理稍微复杂一点的情况:
func = lambda x : "合格了" if x >= 60 else "没合格"
print(func(64))
3 迭代器
迭代器指的是迭代取值的工具,迭代指的是一个重复的过程,每一次重复都是基于上一次的结果而继续,单纯的重复并不是迭代
count = 0
while count < 5:
print(count)
count += 1
迭代器涉及到把多个值循环取出来的工作,涉及类型包括:列表、字符串、元组、字典、集合、文件
# 现在我们暂时忘记for循环,将下列列表取出
l = ['egon','liu','alex']
list_len = len(l)
while list_len > 0:
list_len = list_len - 1
print(l[list_len])
# 此取值方式是根据索引自减进行的,不适用于没有索引类型的取值(例如字典)
为了解决基于索引取值的局限性,python必须提供一种不依赖于索引的取值方式,就是迭代器
3.1 可迭代对象
在了解迭代器之前,我们首先需要了解一下可迭代对象
在python语法中,但凡内置有__iter__方法的都称之为可迭代的对象,换个说法就是可以使用__iter__方法将可迭代对象转换为迭代器对象

已知可迭代对象:字符串、列表、元组、字典、集合、文件对象
s1 = ''
s1.__iter__()
l = []
l.__iter__()
t = {'a',}
t.__iter__()
d = {'a':1}
d.__iter__()
set = {1,2,3}
set.__iter__()
with open('user',mode='rt',encoding='utf-8') as f:
f.__iter__()
3.2 迭代器
调用可迭代对象下的__iter__方法会将其转换成迭代器对象
d = {'a':1,'b':2,'c':3}
res = d.__iter__()
print(res) # <dict_keyiterator object at 0x0000015A3E5F0270>
转换为迭代器对象之后,可以使用__next__进行取值
d = {'a':1,'b':2,'c':3}
d_iter = d.__iter__()
print(d_iter) # <dict_keyiterator object at 0x0000015A3E5F0270>
# 三次取值会依次取元素,取值次数超过元素数,则报错
print(d_iter.__next__()) # a
print(d_iter.__next__()) # b
print(d_iter.__next__()) # c
print(d_iter.__next__()) # 抛出异常StopIteration
修改循环取值代码
d = {'a':1,'b':2,'c':3}
d_iter = d.__iter__()
while True:
try:
print(d_iter.__next__())
except StopIteration: # 捕捉到错误语法StopIteration执行下方代码
break
try...except...捕捉错误语法,例如上文代码就是捕捉错误语法StopIteration
3.3 for循环的工作原理
其实for循环的工作原理和之前的while循环取值代码是一样的,所以for循环又被称为迭代器循环
dic = {'a':1,'b':2,'c':3}
for k in dic:
print(k)
# 1. dic.__iter__()得到迭代器对象
# 2. 迭代器对象.__next__()拿到一个返回值,然后将返回值复制给k
# 3. 循环往复步骤2,直到抛出异常StopIteration异常,for循环捕捉异常,结束循环
但是我们这里需要注意这么一个问题
dic = {'a':1,'b':2,'c':3}
# 转换为迭代器对象
dic_iter = dic.__iter__()
# 发现迭代器对象也可以进行__iter__转换
dic_iter.__iter__()
# 发现dic_iter和dic_iter.__iter__()的内存地址都没有变化,是否调用一个样
# 3144960901824 3144960901824
print(id(dic_iter),id(dic_iter.__iter__()))
问题来了,迭代器对象的__iter__有什么用?
本文可迭代对象部分提到过,可迭代对象:字符串、列表、元组、字典、集合和文件对象
with open('user',mode='rt',encoding='utf-8') as f:
f.__iter__()
f.__next__()
但是文件对象不只是可迭代对象,他也是迭代器对象,它可以直接调用__next__
with open('user',mode='rt',encoding='utf-8') as f:
print(f.__next__())
print(f.__next__())
而for循环的工作原理是dic.__iter__()得到迭代器对象,而for循环并不知道他是文件对象,也就是说,我们按照for循环的规则进行转写
with open('user',mode='rt',encoding='utf-8') as f:
f_iter = f.__iter__() # 迭代器对象被.__iter__()转成了迭代器对象
while True:
try:
print(f_iter.__next__())
except StopIteration:
break
前文提到过迭代器对象被.__iter__()转成了迭代器对象是不会有任何变化的,但是如果他没有这个功能,在文件对象中就会导致for循环因为不能转变为迭代器对象而导致语法错误
3.4 迭代器的优缺点
基于索引的迭代取值,所有迭代的状态都保存在了索引中,而基于迭代器实现迭代的方式不再需要索引,所有迭代的状态就保存在迭代器中,然而这种处理方式优点与缺点并存:
- 优点
- 为序列和非序列类型提供了一种统一的迭代取值方式。
- 惰性计算:迭代器对象表示的是一个数据流,并非是一次性全部加载到内存,它可以只在需要时才去调用next来计算出一个值,就迭代器本身来说,同一时刻在内存中只有一个值,因而可以存放无限大的数据流,例如一个超级大的文件,python直接把文件对象做成了迭代器对象,在内存中一次性只加载next的那一部分。而对于其他容器类型,如列表,需要把所有的元素都存放于内存中,受内存大小的限制,可以存放的值的个数是有限的。
- 缺点
- 除非取尽,否则无法获取迭代器的长度
- 只能取下一个值,不能回到开始,更像是‘一次性的’,迭代器产生后的唯一目标就是重复执行next方法直到值取尽,否则就会停留在某个位置,等待下一次调用next;若是要再次迭代同个对象,你只能重新调用iter方法去创建一个新的迭代器对象,如果有两个或者多个循环使用同一个迭代器,必然只会有一个循环能取到值。
4 生成器
列表、字符串、元组、字典、集合这些可迭代对象都会因为内存大小被限制,而迭代器是一个数据流,单次只会将一个值放入内存,就没有了这个限制。现在需求是一个无限大小的数据类型,所以需要用到迭代器,但用文件来完成又不合适,这时候就需要用到自定义迭代器,也就是生成器
def func():
print(111)
yield 1
yield 2
yield 3
在函数内一旦存在yield关键字,调用函数并不会执行函数体代码,会返回一个生成器对象,生成器即自定义的迭代器
4.1 什么是生成器
在执行生成器函数的时候,函数并不会像普通函数一样执行,而是会返回一个生成器对象
def func():
print(111)
yield 1
print(222)
yield 2
print(333)
yield 3
v1 = func()
print(v1) # <generator object func at 0x7fdff0014a50>
将生成器对象使用next进行执行,执行到yield时就会暂停保留执行位置返回后面的值,下次执行next时,会从上一次的位置基础上再继续向下执行。
def func():
print(111)
yield 1
print(222)
yield 2
print(333)
yield 3
data = func()
# 生成器就是迭代器
# g_iter = g.__iter__() # 可不写,写不写不会有任何变化
v1 = next(data) # 111
print(v1) # 1
v2 = data.__next__() # 222
print(v2) # 2
v3 = next(data) # 333
print(v3) # 3
v4 = next(data) # 同样超出取值次数超过元素数,则报错StopIteration
# 常用的执行方法
data2 = func()
for item in data2:
print(item)
Tips:
# 他们是同样操作的不同写法
len(a) a.__len__()
iter(g) g.__iter__()
next(g) g.__next__()
4.2 生成器的作用
生成器最大的作用是在取大量数值时的内存优化,我们都使用过range函数,但是我们在使用它生成上亿个数都不会把内存撑爆,如果它是一次性生成,存储起来(比如列表),肯定不会有这个效果
def my_range(start,stop,step=1):
'''my_range(起始位置,结束位置,步长)'''
while start<stop:
yield start
start += step
g = my_range(1,5,2)
print(next(g)) # 1
print(next(g)) # 3
# print(next(g)) # StopIteration
for n in my_range(1,7,2):
print(n) # 可以直接for循环
额外小知识:生成器可以被list
def add():
count =0
while True:
count += 1
yield count
g = add()
list(g)
答案是可以的,list原理和for循环是一样的,会不停的将值放入列表,就会导致内存开始爆炸
4.3 yield表达式
yield既然是表达式x = yield 返回值,就说明他是有东西给x的,而这个东西并不是yield后面的值,而是外面通过send()传过来的值
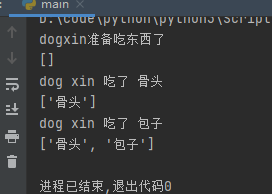
def dog(name):
food_list = []
print('dog%s准备吃东西了'%name)
while True:
x = yield food_list # 通过send传过来的值交给了x
print('dog %s 吃了 %s'%(name,x))
food_list.append(x)
g = dog('xin')
res = g.send(None) # yield 第一次send必须为none
print(res)
res = g.send('骨头')
print(res) # None
res = g.send('包子')
print(res)
# 同样yield也支持解压复制和列表传值
代码从上而下进入,res = g.send(None)相当于next,运行到yield,返回的food_list为空列表,然后,暂停住了,运行外部代码res = g.send('骨头'),send把骨头交给了yield,yield交给了x,继续运行,运行到food_list.append(x),然后开启下一次循环,又遇到了yield,返回了这一次的结果food_list = ['骨头'] 依此类推
代码调用时检测到有yield就会暂停等待send/next,得到命令后需要遇到下一个yield再返回本次结果,并且暂停住等待调用
5 推导式
推导式是Python中提供了一个非常方便的功能,可以让我们通过一行代码实现创建list、dict、tuple、set 的同时初始化一些值
5.1 列表
l = ['yzc_one','lbg_one','amber_two','aym_two']
one_l = []
two_l = []
for name in l:
# endswith如果字符串含有指定的后缀返回 True,否则返回 False。
if name.endswith('one'):
one_l.append(name)
print(one_l)
# 列表生成式
two_l = [name for name in l if name.endswith('two')]
# 列表生成式分为三部分 [结果 for循环 if判断]
# 上诉含义:for name in l 进行循环 if name.endswith('two') 判断成立,就将第一个name放入列表中
print(two_l)
# 也可以不加if判断,就相当于if恒成立,name全部会被放入新列表
three = [name for name in l]
print(three) # ['yzc_one', 'lbg_one', 'amber_two', 'aym_two']
案例
l = ['yzc_one','lbg_one','amber_two','aym_two']
# 把所有小写字母全都变成大写字母
# string.lower()大写转小写 string.upper()小写转大写
new_l1 = [name.upper() for name in l]
print(new_l1) # ['YZC_ONE', 'LBG_ONE', 'AMBER_TWO', 'AYM_TWO']
# 把所有的one名字全去掉后缀
new_l2 = [name.split('_')[0] for name in l if name.endswith('one')]
print(new_l2) # ['yzc', 'lbg']
new_l3 = [name.replace('_one','') for name in l]
print(new_l3) # ['yzc', 'lbg', 'amber_two', 'aym_two']
5.2 字典
keys = ['name','age','gender']
items = {key:None for key in keys}
print(items)
# 生成字典不要gender
item = [('name','egon'),('age',18),('gender','male')]
# 转换为字典,但不要gender这一组
# k,v in item 为解压操作
res = {k:v for k,v in item if k != 'gender'}
print(res)
5.3 集合
l = ['kinght','yzc','aym','lbg']
dict = {name for name in l}
print(dict)
5.4 元组
不会立即执行内部循环去生成数据,而是得到一个生成器。
g = (i for i in range(10) if i>3)
print(g,type(g)) # <generator object <genexpr> at 0x00000120D0937BA0> <class 'generator'>
报错显示,这是一个生成器对象,我们先回到生成式,生成式的本质是
for i in range(10):
if i > 3 :
g.append
而g是元组,元组是无序的无法执行append,所以,他直接成为了生成器,通过生成器进行使用
g = (i for i in range(10) if i<3)
print(g.__next__())
print(g.__next__())
print(g.__next__())
案例:统计文件字符
# 方案一 : 代码太复杂
with open('user',mode='rt',encoding='utf-8') as f:
res = 0
for line in f:
res += len(line)
print(res)
# sum : 求累加和 sum += xx 支持可迭代对象
# 方案二 : 如果文件行数过多也会造成内存负担
with open('user',mode='rt',encoding='utf-8') as f:
res = sum([len(line) for line in f])
print(res)
# 方案三 : 使用生成器 - 每次只出现一行代码
with open('user',mode='rt',encoding='utf-8') as f:
# 这里直接生成可迭代对象
res = sum((len(line) for line in f))
print(res)
with open('user', mode='rt', encoding='utf-8') as f:
# 这里可以省略一组括号,默认识别为生成器
res1 = sum(len(line) for line in f)
print(res1)
5.5 推导式嵌套
推导式支持嵌套
data = [ [i,j] for j in range(5) for i in range(10) ]
# 相当于
data = []
for j in range(5):
for i in range(10):
data.append([i,j])