Python开发-007_数据类型_下
本文是数据类型的最后一章,将会介绍集合、None、字典、浮点型,由于篇幅和安排,将会省略具体内存空间的缓存和暂留机制,放于后文介绍。
1 集合(set)
集合是一个 无序 、可变、不允许数据重复的容器,它的存放元素类型必须满足可哈希的条件。
v = {11,22,(33,44),'aa'}
print(type(v))
集合的存储原理:
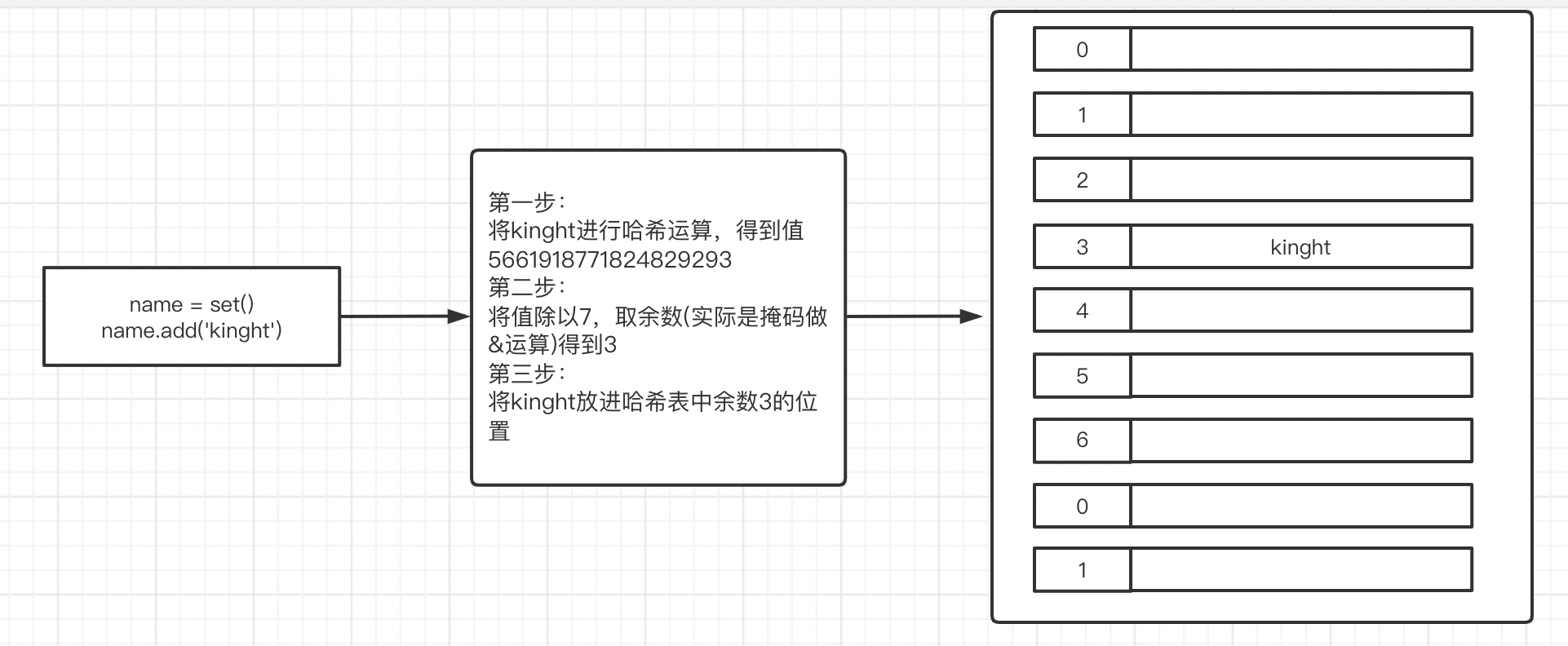
因存储原理,集合的元素必须是可哈希的值,即:内部通过通过哈希函数把值转换成一个数字。
print(hash('kinght'))
print(hash(('kinght','aym')))
print(hash(7777))
print(hash(True))
目前可哈希的数据类型:int、bool、str、tuple,而list、set、dict是不可哈希的。
总结:集合的元素只能是 int、bool、str、tuple 。
1.1 定义
v1 = { 11, 22, 33, "kinght" }
- 无序,无法通过索引取值
- 可变,可以添加或删除元素
v1 = {11,22,33,44}
v1.add(55)
print(v1) # {11,22,33,44,55} # 55的位置是说不准的,集合是无序的
- 不允许数据重复
v1 = {11,22,33,44}
v1.add(22)
print(v1) # {11,22,33,44}
一般什么时候用集合呢?
就是想要维护一大堆不重复的数据时,就可以用它。比如:做爬虫去网上找图片的链接,为了避免链接重复,可以选择用集合去存储链接地址。
注意:定义空集合时,只能使用v = set(),不能使用 v={}(这样是定义一个空字典)。
# 空列表
v1 = []
v11 = list()
# 空元组
v2 = ()
v22 = tuple()
# 空集合 -> 唯一的创建方式
v3 = set()
# 空字典
v4 = {}
v44 = dict()
1.2 独有功能
1.2.1 添加元素
data = {"刘嘉玲", '关之琳', "王祖贤"}
data.add("郑裕玲")
print(data)
# 案例
data = set()
data.add("周杰伦")
data.add("林俊杰")
print(data)
1.2.2 删除元素
data = {"刘嘉玲", '关之琳', "王祖贤","张曼?", "李若彤"}
data.discard("关之琳") # 没有不会报错
print(data)
1.2.3 交集
s1 = {"刘能", "赵四", "???"}
s2 = {"刘科?", "冯乡?", "???"}
# 取两个集合的交集
# 方案1
s4 = s1.intersection(s2)
print(s4) # {"???"}
# 方案2
s3 = s1 & s2
print(s3)
1.2.4 并集
s1 = {"刘能", "赵四", "???"}
s2 = {"刘科?", "冯乡?", "???"}
# 取两个集合的并集
# 方案1
s4 = s1.union(s2) {"刘能", "赵四", "???","刘科?", "冯乡?", }
print(s4)
# 方案2
s3 = s1 | s2 # 取两个集合的并集
print(s3)
1.2.5 差集
s1 = {"刘能", "赵四", "???"}
s2 = {"刘科?", "冯乡?", "???"}
# 取两个集合的差距 -> 顺序决定谁取谁
# 方案1
s4 = s1.difference(s2) # 差集,s1中有且s2中没有的值 {"刘能", "赵四"}
s6 = s2.difference(s1) # 差集,s2中有且s1中没有的值 {"刘科?", "冯乡?"}
# 方案2
s3 = s1 - s2 # 差集,s1中有且s2中没有的值
s5 = s2 - s1 # 差集,s2中有且s1中没有的值
print(s5,s6)
1.3 公共功能
1.3.1 减,计算差集
s1 = {"刘能", "赵四", "???"}
s2 = {"刘科?", "冯乡?", "???"}
# 顺序决定谁取谁
s3 = s1 - s2
s4 = s2 - s1
print(s3) # {'赵四', '刘能'}
print(s4) # {'刘科?', '冯乡?'}
1.3.2 &,计算交集
s1 = {"刘能", "赵四", "???"}
s2 = {"刘科?", "冯乡?", "???"}
s3 = s1 & s2
print(s3) # {'???'}
1.3.3 |,计算并集
s1 = {"刘能", "赵四", "???"}
s2 = {"刘科?", "冯乡?", "???"}
s3 = s1 | s2
print(s3) # {'刘能', '冯乡?', '刘科?', '赵四', '???'}
1.3.4 长度
v = {"刘能", "赵四", "尼古拉斯"}
data = len(v)
print(data) # 3
1.3.5 for循环
v = {"刘能", "赵四", "尼古拉斯"}
for item in v:
print(item)
1.4 转换
其他类型如果想要转换为集合类型,可以通过set进行转换,并且如果数据有重复自动剔除。
提示:int/list/tuple/dict都可以转换为集合。
# 字符串
v1 = "kinght"
v2 = set(v1)
print(v2) # {'k', 'g', 't', 'h', 'n', 'i'}
# 列表
v1 = [11,22,33,11,3,99,22]
v2 = set(v1)
print(v2) # {11,22,33,3,99}
# 元组
v1 = (11,22,3,11)
v2 = set(v1)
print(v2) # {11,22,3}
# 案例 -> 数据去重
data = {11,22,33,3,99}
v1 = list(data) # [11,22,33,3,99]
v2 = tuple(data) # (11,22,33,3,99)
1.5 其他
1.5.1 元素查找速度特别快
因存储原理特殊,集合的查找效率非常高(数据量大了才明显)
- 查找速度慢,需要一个一个检索值的索引,然后再查询值
user_list = ["kinght","aym","ayi"]
if "kinght" in user_list:
print("在")
else:
print("不在")
user_tuple = ("kinght","aym","ayi")
if "aym" in user_tuple:
print("在")
else:
print("不在")
- 查找速度快,直接查询值
user_set = {"kinght","aym","ayi"}
if "kkk" in user_set:
print("在")
else:
print("不在")
1.5.2 对比和嵌套
嵌套同样遵循是否可哈希的原则,可哈希就可以被嵌套。
| 类型 | 是否可变 | 是否有序 | 容器元素要求 | 是否可哈希 | 转换 | 定义空 |
|---|---|---|---|---|---|---|
| list | 是 | 是 | 无 | 否 | list(其他) | v=[]或v=list() |
| tuple | 否 | 是 | 无 | 是 | tuple(其他) | v=()或v=tuple() |
| set | 是 | 否 | 可哈希 | 否 | set(其他) | v=set() |
data_list = [
"alex",
11,
(11, 22, 33, {"alex", "eric"}, 22),
[11, 22, 33, 22],
{11, 22, (True, ["中国", "北京"], "沙河"), 33} # 列表不能哈希,所以报错
]
注意:由于True和False本质上存储的是 1 和 0 ,而集合又不允许重复,所以在整数 0、1和False、True出现在集合中会有如下现象:
v1 = {True, 1}
print(v1) # {True} True和False在计算机中是1和0表示的,所以集合会只有一个True
v2 = {1, True}
print(v2) # {1}
v3 = {0, False}
print(v3) # {0}
v4 = {False, 0}
print(v4) # {False}
2 None类型
Python的数据类型中有一个特殊的值None,意味着这个值啥都不是 或 表示空。 相当于其他语言中 null作用一样。
在做预定义变量的时候,使用None可以在一定程度上可以帮助我们去节省内存(注意:暂不要考虑Python内部的缓存和驻留机制,具体情况后文介绍)
v1 = None
v2 = None
..
v1 = [11,22,33,44]
v2 = [111,22,43]
v3 = [] # 创建空列表,内存会开辟列表所需要的空间
v4 = []
...
v3 = [11,22,33,44]
v4 = [111,22,43]
3 字典(dict)
字典是 无序、键不重复 且 元素只能是键值对的可变的 个 容器。
data = {key:value,key:value}
我们可以单纯理解,他的key是集合类型,而value是任意类型。
-
容器
-
元素必须键值对
-
键不重复,重复则会被覆盖
data = {"k1":1,"k1":2}
print(data) # {"k1":2}
-
无序(在Python3.6+字典就是有序了,之前的字典都是无序。)
但是,这里就算是有序了,也不能通过索引取值
data = {"k1":1,"k2":2}
print(data)
字典与元祖的存储原理相似,但是只对key做哈希处理
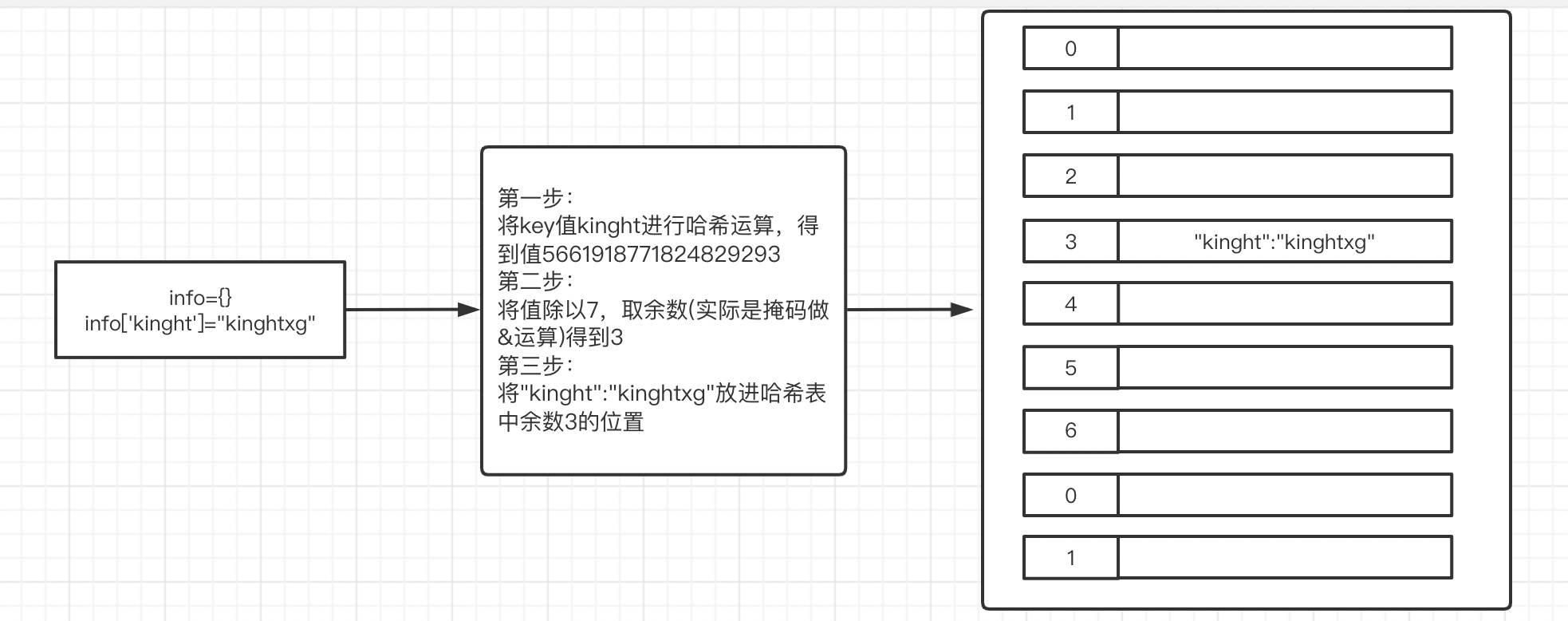
3.1 定义
# 两种定义模式
v1 = {}
v2 = dict()
# 案例
info = {
"age":12,
"status":True,
"name":"wupeiqi",
"hobby":['篮球','足球']
}
字典中对键值得要求:
- 键:必须可哈希。 目前为止学到的可哈希的类型:int/bool/str/tuple;不可哈希的类型:list/set/dict。(集合)
- 值:任意类型。
# 合法的定义
data_dict = {
"武沛齐":29,
True:5,
123:5,
(11,22,33):["alex","eric"]
}
# 不合法的定义
v1 = {
[1, 2, 3]: '周杰伦',
"age" : 18
}
v2 = {
{1,2,3}: "哈哈哈",
'name':"alex"
}
v3 = {
{"k1":123,"k2":456}: '呵呵呵',
"age":999
}
注意:同样True会被当作1,所以会被覆盖掉
data_dict = {
1: 29,
True: 5 # 同样True会被当作1,所以会被覆盖掉
}
print(data_dict) # {1: 5}
一般在什么情况下会用到字典呢?
当我们想要表示一组固定信息时,用字典可以更加的直观,例如:
# 用户列表
user_list = [ ("alex","123"), ("admin","666") ]
...
# 用户列表
user_list = [ {"name":"alex","pwd":"123"}, {"name":"eric","pwd":"123"} ]
3.2 独有功能
3.2.1 获取值
get取值
info = {
"age":12,
"status":True,
"name":"武沛齐",
"data":None
}
# get取值
data1 = info.get("name")
print(data1) # 输出:武沛齐
data2 = info.get("age")
print(data2) # 输出:12
data = info.get("email") # 键不存在,默认返回 None
查看键是否存在
info = {
"age":12,
"status":True,
"name":"武沛齐",
"data":None
}
if data == None:
print("此键不存在")
else:
print(data)
if data: # 不存在则返回None,None == False
print(data)
else:
print("键不存在")
# 改进
## 判断info字典的键中是否存在email
if "email" in info: # 判断email是否存在于字典key中
data = info.get("email")
print(data)
else:
print("不存在")
### 存在问题:如果字典中有"email":None的元素,则此判断不准确
## 改进
### 直接一步到位如果key="hobby"存在返回值value,不存在返回123
data = info.get("hobby",123)
print(data) # 输出:123
# 案例:
user_list = {
"wupeiqi": "123",
"alex": "uk87",
}
username = input("请输入用户名:")
password = input("请输入密码:")
# None,用户名不存在
# 密码,接下来比较密码
pwd = user_list.get(username)
if not pwd:
print("用户名不存在")
else:
if password == pwd:
print("登录成功")
else:
print("密码错误")
# 写代码的准则:简单的逻辑处理放在前面;复杂的逻辑放在后面。
3.2.2 获取所有的键
info = {"age":12, "status":True, "name":"wupeiqi","email":"xx@live.com"}
data = info.keys() # 获取所有的键
print(data)
# 输出:
## py3 -> dict_keys(['age', 'status', 'name', 'email'])
## py2 -> ['age', 'status', 'name', 'email']
注意:在Python2中 字典.keys()直接获取到的是列表,而Python3中返回的是高仿列表,这个高仿的列表可以被循环显示。
ps:高仿的列表作用是缓存,他可以节省内存,具体方式在生成器篇章讲到
# 高仿列表转列表
result = list(data)
3.2.3 获取所有的值
info = {"age":12, "status":True, "name":"wupeiqi","email":"xx@live.com"}
data = info.values()
print(data) # 输出:dict_values([12, True, 'wupeiqi', 'xx@live.com'])
注意:与获取所有的键相同,在Python2中 字典.values()直接获取到的是列表,而Python3中返回的是高仿列表,这个高仿的列表可以被循环显示。
3.2.4 获取所有的键值对
info = {"age":12, "status":True, "name":"wupeiqi","email":"xx@live.com"}
data = info.items()
print(data)
# 输出 dict_items([ ('age', 12), ('status', True), ('name', 'wupeiqi'), ('email', 'xx@live.com') ])
# 可以使用for循环,获取直接拆分
# 方案1
for item in info.items():
print(item[0],item[1]) # item是一个元组 (键,值)
# 方案2 -> 推荐
for key,value in info.items():
print(key,value) # key代表键,value代表值,将兼职从元组中直接拆分出来了。
3.2.5 设置值
data = {
"name": "武沛齐",
"email": 'xxx@live.com'
}
data.setdefault("age", 18)
print(data) # {'name': '武沛齐', 'email': 'xxx@live.com', 'age': 18}
# key不存在,则添加,key存在则不改变value
data.setdefault("name", "alex")
print(data) # {'name': '武沛齐', 'email': 'xxx@live.com', 'age': 18}
3.2.6 更新字典键值对
info = {"age":12, "status":True}
info.update( {"age":14,"name":"武沛齐"} )
# info中没有的键直接添加;有的键则更新值
print(info) # 输出:{"age":14, "status":True,"name":"武沛齐"}
3.2.7 移除指定键值对
info = {"age":12, "status":True,"name":"武沛齐"}
data = info.pop("age")
# 移除掉的同时会将值传递给data
print(info) # {"status":True,"name":"武沛齐"}
print(data) # 12
3.2.8 按照顺序移除(后进先出)
- py3.6后,popitem移除最后的值。
- py3.6之前,popitem随机删除。
info = {"age":12, "status":True,"name":"武沛齐"}
data = info.popitem() # 移除掉最后的值,将被移除的值组成元组
# ("name","武沛齐" ) -> data
print(info) # {"age":12, "status":True}
print(data) # ("name","武沛齐")
3.3 公共功能
3.3.1 求并集(Python3.9新加入)
v1 = {"k1": 1, "k2": 2}
v2 = {"k2": 22, "k3": 33}
v3 = v1 | v2
print(v3) # {'k1': 1, 'k2': 22, 'k3': 33}
3.3.2 长度
info = {"age":12, "status":True,"name":"武沛齐"}
data = len(info)
print(data) # 输出:3
3.3.3 是否包含
判断是否在key里面
info = { "age":12, "status":True,"name":"武沛齐" }
v1 = "age" in info # 判断是否在key里面
print(v1)
v2 = "age" in info.keys()
print(v2)
判断是否在value里面
info = {"age":12, "status":True,"name":"武沛齐"}
v1 = "武佩奇" in info.values()
print(v1)
判断键值对是否在字典里
info = {"age": 12, "status": True, "name": "武沛齐"}
v1 = ("age", 12) in info.items()
print(v1)
# 输出info.items()获取到的 dict_items([ ('age', 12), ('status', True), ('name', 'wupeiqi'), ('email', 'xx@live.com') ])
3.3.4 索引(键)
就算是有序了,也不支持0,1,2进行取值
字典不同于元组和列表,字典的索引是键,而列表和元组则是 0、1、2等数值 。
info = { "age":12, "status":True, "name":"武沛齐"}
print( info["age"] ) # 输出:12
print( info["name"] ) # 输出:武沛齐
print( info["status"] ) # 输出:True
print( info["xxxx"] ) # 报错,不存在会报错
# 通过get取值时,键不存在会报错(以后项目开发时建议使用get方法根据键去获取值)
value = info.get("xxxxx") # None
print(value)
3.3.5 根据键 修改值 和 添加值 和 删除键值对
上述示例通过键可以找到字典中的值,通过键也可以对字典进行添加和更新操作
增、改
# 增、改为一体
# 原值没有则新增,存在则修改
# 增
info = {"age":12, "status":True,"name":"武沛齐"}
info["gender"] = "男"
print(info) # 输出: {"age":12, "status":True,"name":"武沛齐","gender":"男"}
# 改
info = {"age":12, "status":True,"name":"武沛齐"}
info["age"] = "18"
print(info) # 输出: {"age":"18", "status":True,"name":"武沛齐"}
删除
info = {"age":12, "status":True,"name":"武沛齐"}
# 删除info字典中键为age的那个键值对(键不存在则报错)
del info["age"]
# 删除info字典中键为status的那个键值对(键不存在则报错)
data = info.pop("status") # 但是pop可以取值
print(info) # 输出: {"name":"武沛齐"}
print(data) # True
3.3.6 for循环
由于字典也属于是容器,内部可以包含多个键值对,可以通过循环对其中的:键、值、键值进行循环;
# 循环取键
# 方案1 -> 默认取出就是键
info = {"age":12, "status":True,"name":"武沛齐"}
for item in info:
print(item) # 默认是所有键
# 方案2
info = {"age":12, "status":True,"name":"武沛齐"}
for item in info.key():
print(item)
# 循环取值
info = {"age":12, "status":True,"name":"武沛齐"}
for item in info.values():
print(item)
# 循环取键值对
info = {"age":12, "status":True,"name":"武沛齐"}
for key,value in info.items():
print(key,value)
3.4 转换
只有成对的列表和元组才能转换为字典
# 转换时要求成对存放
v = dict( [ ("k1", "v1"), ["k2", "v2"] ] )
v = dict( ( ("k1", "v1"), ["k2", "v2"] ) )
# 可以是列表也可以是元组
print(v) # { "k1":"v1", "k2":"v2" }
元组取出则是伪列表
info = { "age":12, "status":True, "name":"武沛齐" }
v1 = list(info) # ["age","status","name"]
# 伪列表转列表需要使用list
v2 = list(info.keys()) # ["age","status","name"]
v3 = list(info.values()) # [12,True,"武沛齐"]
v4 = list(info.items()) # [ ("age",12), ("status",True), ("name","武沛齐") ]
3.5 其他
3.5.1 速度快
# 通过值查找键是否在字典内非常快
info = {
"alex":["肝胆","铁锤"],
"老男孩":["二蛋","缺货"]
}
for "alex" in info:
print("在")
# 通过键取值非常快
info = {
"alex":["肝胆","铁锤"],
"老男孩":["二蛋","缺货"]
}
v1 = info["alex"]
v2 = info.get("alex")
3.5.2 嵌套
- 字典的键必须可哈希(list/set/dict不可哈希)。
info = {
(11,22):123
}
# 错误 -> 和集合一样,无论是否嵌套,key内的值都必须可哈希
info = {
(11,[11,22,],22):"alex"
}
- 字典的值可以是任意类型。
info = {
"k1":{12,3,5},
"k2":{"xx":"x1"}
}
- 字典的键和集合的元素在遇到 布尔值 和 1、0 时,需注意重复的情况。
4 浮点型(float)
浮点型,一般在开发中用于表示小数。
关于浮点型的其他知识点如下:
-
在类型转换时需要,在浮点型转换为整型时,会将小数部分去掉。
v1 = 3.14 data = int(v1) print(data) # 3 -
想要保留小数点后N位
v1 = 3.1415926 result = round(v1,3) # 会完成四舍五入 print(result) # 3.142
注意:浮点型的坑(所有语言都有)
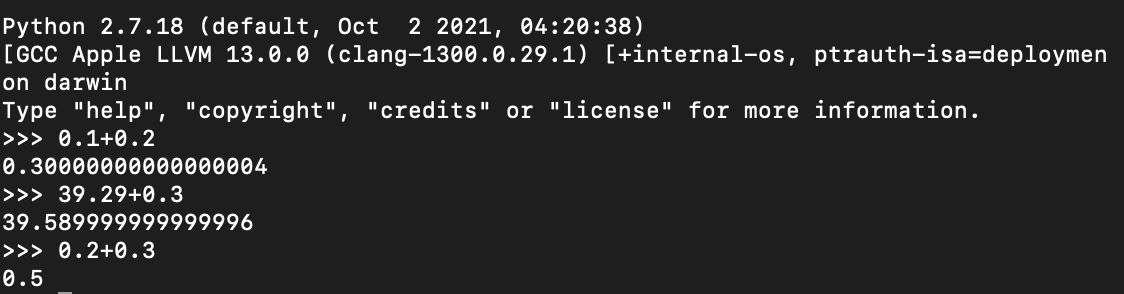
0.1+0.2到底等于多少?
我们使用python2进行一下计算,可以感觉到,和我们的认知有一点点的差距!
总所周知,计算机中小数使用浮点型表示的,浮点型在计算机中存储同样需要转换为二进制表示,整数部分直接采用二进制即可,小数部分则采用了一种特殊的处理办法。

我们以39.29为例,整数部分直接取二进制100111,小数部分则如上图所示,把小数部分乘以2,如果小于0,则取数字为0,大于0则取数字1,将整数部分抛弃,继续取小数部分,直到该数字刚好等于1为止。然后将数字进行排列,就是他的二进制表示了。
不过在这中间很可能会导致小数部分循环(最后一行与第三行),导致数字不可能取完。
把39.29转换为二进制,还需要将二进制转为科学技术法,就是将小数点向左移动5位,即2的5次方:

假如:浮点型,整数部分为0,则需要小数点则需要右移
0.0010111 -> 1.0111 * 2的负三次方
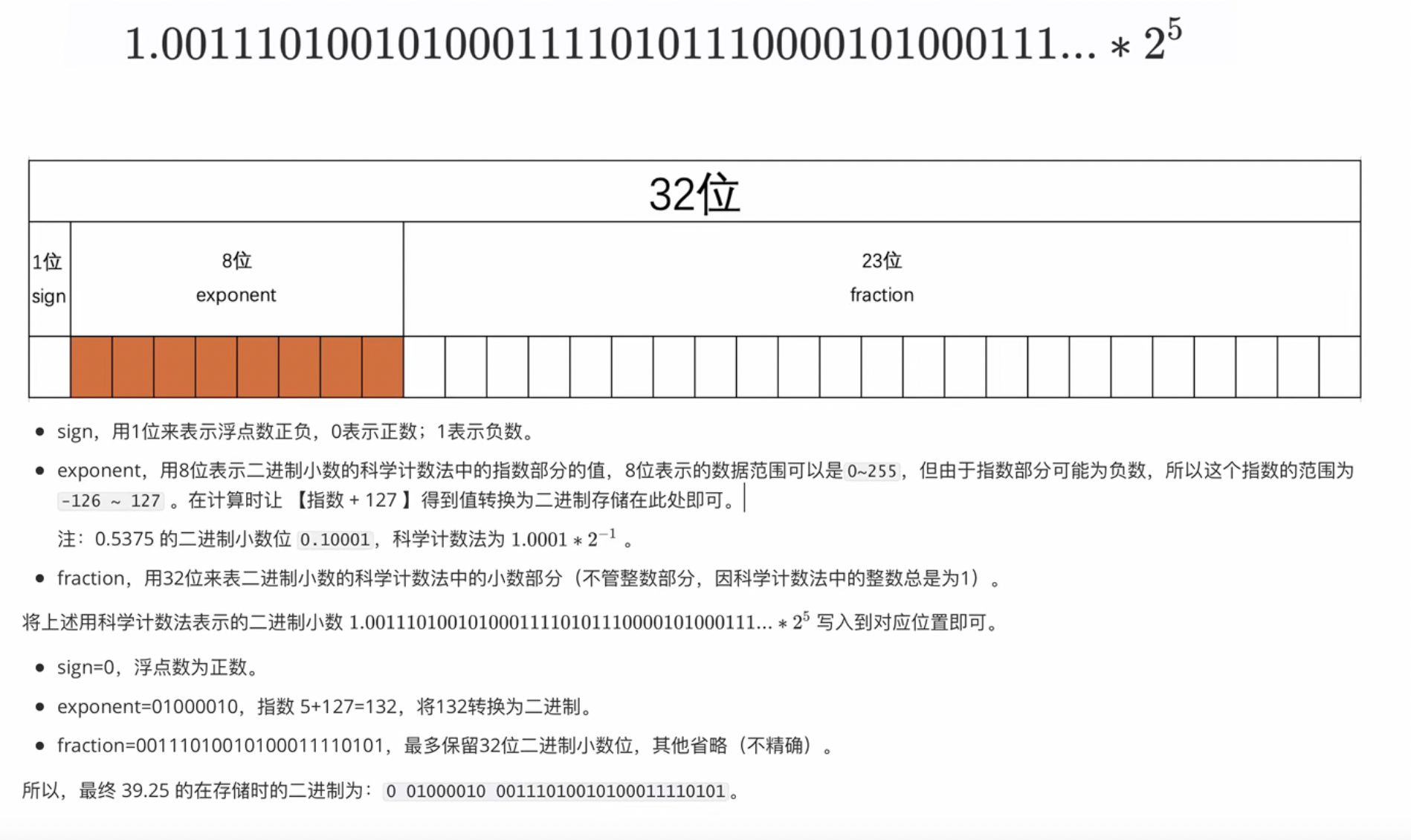
然后这里以浮点型的单精度为例(32位,双精度64位),将数据填入内存中,还有1位正副位,和8位科学技术法的指令位,只有23位是真正存储数据的,而超过23位的部分,计算机就只能选择丢弃,所以导致精度有限。
在项目中如果遇到精确的小数计算应该怎么办?
# python提供了一个库叫做decimal,可以做精准运算
import decimal
v1 = decimal.Decimal("0.1")
v2 = decimal.Decimal("0.2")
v3 = v1 + v2
print(v3) # 0.3