Python开发-009_函数基础与文件操作
本章将会进入函数的学习,在深入学习之前,我们先来了解一下,什么是函数?
1 函数简介
在我们之前的代码中,我们是在一个.py文件内部,根据代码的执行逻辑,一步一步的将代码进行编写,但是这就会遇到一个问题。
# 格式化输出个人信息
name = "kinght"
age = 20
sex = "man"
print("username = {} \nage = {} \nsex = {}".format(name,age,sex))
name = "aym"
age = 18
sex = "woman"
print("username = {} \nage = {} \nsex = {}".format(name,age,sex))
按照之前的方式进行输出,我们需要有多少人就这样输出一次,两个人还好,如果几百个人,那么代码量就太过庞大了。
于是乎,就有了函数的概念:
def user(username,userage,usersex):
name = username
age = userage
sex = usersex
print("username = {} \nage = {} \nsex = {}".format(name,age,sex))
# 调用函数
user("kinght",20,"man")
user("aym",18,"woman")
我们使用def对内部的操作进行打包成user函数,并且user函数接受username,userage,usersex的参数进行传入,我们只需要使用函数名(参数)的形式进行调用,就输出了我们需要的格式。
就相当于找了一个代工的人,将操作方法教会了它之后,只用把原材料给他就可以了。
所以总结起来,函数,一个用于专门实现某个功能的代码块(可重用)
1.1 内置函数
python解释器默认内置了很多函数,我们在之前已经使用过了其中的一部分
len、bin、oct、hex 等
1.2 自定义函数
如上诉代码,这个函数不是python内置,而是程序员自己编写的函数叫做自定义函数
def send_eamil():
pass
def send_wchat():
pass
send_eamil()
send_wchat()
1.3 模块
例如:现有两个文件send.py和main.py
Send.py
def send_mail():
pass
def send_wchat():
pass
Main.py
import send
send.send_mail()
send.send_wchat()
我们可以将函数放在一个单独的.py文件中,这个文件就被称为模块。
同样模块可以根据来源进行分类:
- 内置模块,python解释器提供的模块
import random
print(random.randint(0,100))
-
第三方模块,从网上下载别的程序员写的模块
-
自定义模块,自己写的模块
2 文件操作相关
文件操作需要使用到很多的函数,所以我们将其作为函数入门进行学习
在进行具体的文件操作之前,我们需要对编码和相关数据类型进行回顾
-
字符串类型(str),在程序中用于表示文字信息,本质是unicode编码的二进制
-
字节类型(byte)
- 可表示文字信息,本质是utf-8/gbk等编码的二进制(对unicode编码进行压缩,方便传输)
name = '马化腾' data = name.encode("utf-8") print(data) # b'\xe9\xa9\xac\xe5\x8c\x96\xe8\x85\xbe' rester = data.decode('utf-8') print(rester) # 马化腾- 可表示原始二进制(图片、文件等信息)
2.1 读文件
读取文件分几步?和把大象装冰箱一样分三步,打开文件、读取文件、关闭文件。
2.1.1 读取文本文件
# 1.打开文件
# r = 读取文件 b = 二进制内容
file_object = open('123.txt',mode='rb')
# 2.读取文件
# .read() 读取所有的文件内容,赋值给data
data = file_object.read()
# 3.关闭文件
file_object.close()
print(data)
# 字节类型
# b'12312312\n231241241\n123124124\n21312341'
text = data.decode("utf-8") # 字节转字符串
print(text)
'''
输出结果
12312312
231241241
123124124
21312341
'''
在文件I/O中,要从一个文件读取数据,应用程序首先要调用操作系统函数并传送文件名,并选一个到该文件的路径来打开文件。该函数取回一个顺序号,即文件句柄(file handle),该文件句柄对于打开的文件是唯一的识别依据。要从文件中读取一块数据,应用程序需要调用函数ReadFile,并将文件句柄在内存中的地址和要拷贝的字节数传送给操作系统。当完成任务后,再通过调用系统函数来关闭该文件。
补充知识:
-
相对路径
-
相对于使用文件而言的路径
/tmp/code/python文件夹 duqu.py 123.txt /tmp/code/java文件夹 111.txt 对于duqu.py的相对路径 123.txt -> 123.txt(相同文件夹直接写文件名即可) 111.txt -> ../java/111/txt(相对duqu.py在另一个上级文件阿吉,所以需要先回到上级目录../,然后在进入对应文件夹找到目录111.txt)
-
-
绝对路径
-
对于系统目录而言的路径
/tmp/code/python文件夹 duqu.py 123.txt /tmp/code/java文件夹 111.txt 对于duqu.py的绝对路径 123.txt -> /tmp/code/python/123.txt 111.txt -> /tmp/code/java/111.txt
-
每次读取文件都需要decode未免显得太过麻烦,所以其实可以直接用rt模式
# r读取,t文本内容。 encoding="utf-8" 编码成utf-8
file_object = open('123.txt',mode='rt',encoding="utf-8")
data = file_object.read()
file_object.close()
print(data)
2.1.2 读取图片等非文本内容文件
file_object = open('123.jpeg',mode='rb')
data = file_object.read()
file_object.close()
print(data)
# 图片等原始二进制内容
# b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\...后续内容省略
2.1.3 读文件注意事项
-
路径
-
相对路径
- 要明白现在的程序运行路径
使用终端运行的时候 python3 /Users/kinght/code/python/lufei/hanshu 程序内的相对地址也是当前运行路径(pwd)为基准,而不是以程序文件地址为基准 Traceback (most recent call last): File "/Users/kinght/code/python/lufei/hanshu/day7/4/rtduwenjian.py", line 1, in <module> file_object = open('123.txt',mode='rt',encoding="utf-8") FileNotFoundError: [Errno 2] No such file or directory: '123.txt' -
绝对路径
# 修改代码使用绝对路径 file_object = open('/Users/kinght/code/python/lufei/hanshu/day7/4/123.txt',mode='rb') # 运行代码 python3 /Users/kinght/code/python/lufei/hanshu/day7/4/rtduwenjian.py就不会出现报错

这里需要注意:windows的路径
c:\new\windows\123.txt可能会导致\+n = \n的情况出现,变成转义符号# 解决方案1 -> 先一步使用转义符号 转义成\: file_object = open('c:\\new\\windows\\123.txt',mode='rb') # 解决方案2 -> 使用r使其不转义: file_object = open(r'c:\new\windows\123.txt',mode='rb') -
-
读文件时,文件不存在会报错
file_object = open('1234.txt',mode='rt',encoding="utf-8") data = file_object.read() file_object.close() print(data) # 报错 Traceback (most recent call last): File "/Users/yangzhichao/code/python/lufei/hanshu/day7/4/rtduwenjian.py", line 1, in <module> file_object = open('1234.txt',mode='rt',encoding="utf-8") FileNotFoundError: [Errno 2] No such file or directory: '1234.txt'判断路径是否存在
import os exists = os.path.exists("1234.txt") print(exists) # 存在返回True 不存在返回False
2.2 写文件
2.2.1 写入文本文件
# 1.打开文件
# 使用wb,w写入b字节类型 -> 会要求写入时是字节类型
file_object = open('111.txt', mode='wb')
# 2.写入内容 -> write就是写入
file_object.write("狗策划!退钱".encode("utf-8"))
# 3.关闭文件
file_object.close()
然后运行文件,会发现在项目目录下生成了
同样的可以使用wt模式,省略编码过程
# 1.打开文件
# 使用wb,w写入t文本类型
file_object = open('111.txt', mode='wt',encoding='utf-8')
# 2.写入内容
file_object.write("狗策划!退钱")
# 3.关闭文件
file_object.close()
2.2.2 写入非文本文件
由于非文本文件都是一个个字节组成的,图片其实就是一个个点像素点信息,所以这里采取先复制,在写入的方式进行
# 读取图片信息
f1 = open("123.png",mode='rb')
data = f1.read()
f1.close()
# 写入图片信息
f2 = open("222.png",mode='wb')
f2.write(data)
f2.close()
注意:使用w打开文件句柄的时候,会将文件清空!
# 案例 - 多用户注册
user_file = open("user.txt",mode='wt',encoding='utf-8') # 为了可以连续写入,将文件打开放于循环之外
while True:
print("注册(输入Q结束)".center(21,"*"))
user = input("请输入用户名:")
if user.upper() == 'Q':
break
passwd = input("请输入密码:")
data = "{}-{}\n".format(user,passwd) # \n是为了换行
# user_file = open("user.txt",mode='wb',encoding='utf-8')
# 每次打开文件wb都会清空文件
user_file.write(data)
user_file.close()
举个??:https://kinghtxg.com/archives/python-cong-wang-luo-zhong-bao-cun-wen-jian-he-tu-pian-de-ji-chu
2.2.3 写文件的注意事项
- 路径
- 写文件同样遵循绝对路径和相对路径
- 当文件不存在时,w模式会创建文件,而文件存在时,w模式会清空文件后写入内容
2.3 文件操作的打开模式
上文我们基于文件操作基本实现了读、写的功能,其中涉及的文件操作模式:rt、rb、wt、wb,其实在文件操作中还有其他的很多模式。
========= ===============================================================
Character Meaning
--------- ---------------------------------------------------------------
'r' open for reading (default)
'w' open for writing, truncating the file first
'x' create a new file and open it for writing
'a' open for writing, appending to the end of the file if it exists
'b' binary mode
't' text mode (default)
'+' open a disk file for updating (reading and writing)
The default mode is 'rt' (open for reading text).
以上时官方对于文件打开模式的介绍,我们将其分为了三个部分阅读。
- 第一部分
r\w\x\ar是读取文件操作w\x\a是写入文件操作w-> 文件无论是否存在,都进行清空后写入x-> 文件不存在创建写入,文件存在就报错a->打开文件往尾部进行追加,不会清空文件
- 第二部分
b\t,指定文本模式还是二进制模式b->字节模式,底层数据时是二进制形式存在t->文本模式,需要后方添加encoding="编码格式"(不添加为系统默认当前文档格式)
常见组合:
# 只读模式
r\rt\rb
## r模式默认 == rt
## 文件存在即可读,不存在即报错
# 只写模式
w\wt\wb
## w模式默认 == wt
## 文件存在清空再写、不存在创建再写
x\xt\xb
## x模式默认 == xt
## 文件存在则报错,不存在则创建再写
a\at\ab
## a模式默认 == at
## 存在就尾部追加,不存在就创建再写,不会清空文件
-
第三部分
+,即可读又可写,不过会根据模式不同导致光标位置不同-
r+、rt+、rb+,文件需要提前存在,默认光标位置:起始位置
file_object = open('demo1.txt', mode='rt+') # 读取内容 data = file_object.read() print(data) # HI,Friends # 写入内容 file_object.write("你好呀") file_object.close()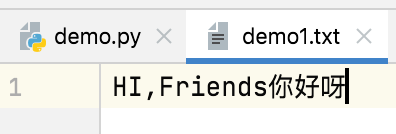
-
w+、wt+、wb+,默认光标位置:起始位置(清空文件)
file_object = open('demo1.txt', mode='wt+') # 读取内容 data = file_object.read() print(data) # 文件被清空了,读取不到内容 # 写入内容 file_object.write("你好呀") file_object.close()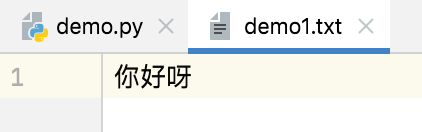
-
x+、xt+、xb+,默认光标位置:起始位置(新文件)
file_object = open('demo2.txt',mode='xt+') # 写入内容 file_object.write("你好呀") # 移动文件内光标 p = file_object.tell() print(p) # 9 由于同一次文件打开,检查光标已经被移动到9的位置 file_object.seek(0) # 将光标从新移动到文件开头,才能读取到刚写入的内容 # 读取内容 data = file_object.read() print(data) # 你好呀 file_object.close()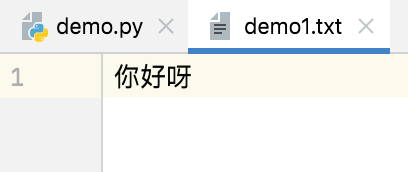
-
a+、at+、ab+,默认光标位置:末尾
file_object = open('demo2.txt',mode='at+') # 读取内容 ## 光标置于末尾,无法读取内容 data = file_object.read() print(data) # 写入内容 file_object.write("你好呀") file_object.close()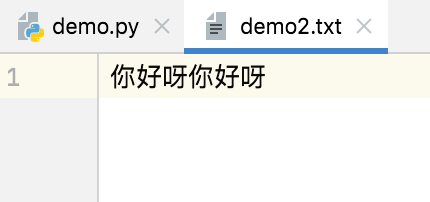
-
完善前文注册案例(多用户注册系统):
# 多用户注册案例
# 注册模块
def registered():
print("欢迎来到用户注册系统".center(25, '*'))
user_name = input("请输入用户名:")
user_passwd = input("请输入密码:")
user = "{}-{}\n".format(user_name,user_passwd)
user_file = open('user.txt',mode='at',encoding='utf-8')
user_file.write(user)
user_file.close()
# 登录模块
def login():
print("请用户登录系统".center(25, '*'))
user_name = input("请输入用户名:")
user_passwd = input("请输入密码:")
user_file = open('user.txt',mode='rt',encoding='utf-8')
for user in user_file:
username,passwd = user.strip().split("-",1)
# 注意,由于注册模块存储时加了\n,所以提取时要去掉才能得到准确的passwd
if username == user_name and passwd == user_passwd:
print("登录成功")
break # 多用户时,比较成功了,就break
else: # 如果没有比较到,就显示登录失败
print("登录失败")
login()
while True:
print("请用户系统".center(25, '*'))
print("1.登录")
print("2.注册")
print("3.退出")
inp = input("请输入:")
if not inp.isdecimal() or 0 <= int(inp) >= 3:
# 两个只要错一个就重新输入
print("输入错误,请重新如数")
continue
if inp == '1':
login()
elif inp == '2':
registered()
else:
break
2.4 文件操作的其他功能
在上述对文件的操作中,我们只使用了write和read来对文件进行读写,其实在文件操作中还有很多其他的功能来辅助实现更好的读写文件的内容。
2.4.1 读
read和readlines由于都会一次性读取所有的文件内容,所以对于内存有一定溢出的危险
f.read()
读取所有内容,执行完该操作后,文件指针会移动到文件末尾
f = open("user.txt",mode='rt',encoding='utf-8')
print(f.read(3)) # rt指定单次读取3字符(如果是rb模式打开是3个bytes数据)
print(f.read()) # 读取完所有内容
f.close()
f.readline()
读取一行内容,光标移动到第二行首部
f = open('user.txt',mode='rt',encoding='utf-8')
print(f.readline()) # admin-admin
print(f.readline()) # kinght-ass
print(f.readline()) # asdasd-asdaaa
f.close()
f.readlines()
当前文件指针为起始,读取每一行内容,并且按行为分割,存放于列表中
f = open('user.txt',mode='rt',encoding='utf-8')
data = f.readlines()
print(data)
# 全部输出,形成列表
# ['admin-admin\n', 'kinght-ass\n', 'asdasd-asdaaa\n', 'abc-abc\n']
for循环读取(redline加强版)
for循环可以按行读取所有的内容,常用语读取大文件
f = open('user.txt',mode='rt',encoding='utf-8')
for i in f:
print(i,end="")
''' 文件中有换行符,所以需要再print的时候取消换行符
admin-admin
kinght-ass
asdasd-asdaaa
abc-abc
'''
使用.read(字节大小)控制单次读取字节数来读取大文件
import os
# 使用os.path.getsize计算文件大小
file_size = os.path.getsize("etl_log.txt.txt")
read_size = 0
with open('etl_log.txt.txt', 'rb') as file_object:
while read_size < file_size:
#.read(字节)控制文件读取大小
data = file_object.read(1)
read_size += len(data)
2.4.2 写
相对于读,写的内容就非常少,在之前已经提到过大部分
f = open("user.txt",mode='at',encoding='utf-8')
f.write("ayi-sssd")
f.close()
flush 刷入硬盘
write进行写入的时候,文件会先写入到系统缓冲区中,缓冲区会定时定量的将内容刷入硬盘
我们可以是用flush将缓冲区内容直接刷入硬盘
user_file = open('user.txt',mode='at',encoding='utf-8')
while True:
username = input('请输入用户名:')
passwd = input('请输入密码:')
user = "{}-{}\n".format(username,passwd)
user_file.write(user)
user_file.flush() # 写入硬盘
user_file.close()
我们可以非常直观的看文件内容,有user_file.flush()在运行过程中文件就可以得到改变,而没有就需要关闭文件后才会改变
光标位置移动
对于光标而言,t/b模式是有区别的,假设文字是汉字,一个汉字等于三个字节,所以,t模式就等于三个字节,而b模式就不需要顾虑,直接表示1个字节
f = open('user.txt',mode='r+t',encoding='utf-8')
# seek() 移动到多少字节(无论模式都是字节,中文就是一个汉字三个字节)
f.seek(4) # admin-admin 移动到第4个字节
print(f.readline()) # n-admin # 读取当前行
f.seek(4) # 回到第4个字节
f.write('你好呀') # 覆盖修改了往后的9个字符
f.seek(0) # 将光标移动到文件开头
print(f.readline()) # admi你好呀inght-ass
f.close()
如果某个字符是3位,取的时候被截断了,就可能报错
f = open('user.txt',mode='r+t',encoding='utf-8')
# 汉字是三个字符,但是被截断了就可能乱码
f.seek(5) # 光标5-7是汉字你,这里直接将光标移动到汉字内部
print(f.readline())
f.close()

需要注意的是:a模式的初始光标在最后方
f = open('中文.txt',mode='a+t',encoding='utf-8')
print(f.tell()) # 517
f.seek(0)
f.read(3) # 这里是中文,所以t模式是移动9个字符
print(f.tell()) # 9
f.close()
补充知识 - 重命名
import shutil
# ha.conf_1重命名为ha.conf 且如果存在就覆盖ha.conf
shutil.move('ha.conf_1','ha.conf')
2.5 上下文管理(推荐使用)
之所以使用上下文管理,是因为在操作文件的时候会占用内存,而文件不关闭是不会报错的,所以就可能导致忘记关闭文件而导致内存不够用的情况发生
with open('中文.txt',mode='rt',encoding='utf-8') as f:
data = f.readline()
print(data)
# 文件只在缩进中打开,缩进之外自动关闭
# f.readline() # 提示文件已被关闭
在python2.7之后,支持同时打开多个文件
# 两个open本应该写在一排中,使用\让他们分割成两排,但其实对于程序是一排
with open('中文.txt',mode='rt',encoding='utf-8') as f,\
open('user.txt',mode='rt',encoding='utf-8') as b:
pass