Python开发-005_数据类型_上
1 数据类型概述
总所周知,在运行程序之前,计算机会讲程序相关的数据提取到内存之中,而变量由于会随着程序的运算,不断变化内部的值,故应该给每个变量在内存中分配多大的空间就成为了一个迷,空间大了浪费,小了不够用,为了方便人们的使用,就诞生了数据类型。
不同数据类型占用的数据空间:
| 序号 | 类型 | 字节数(byte) |
|---|---|---|
| 1 | boolean | 1 |
| 2 | byte | 1 |
| 3 | char | 2 |
| 4 | short | 2 |
| 5 | float | 4 |
| 6 | int | 4 |
| 7 | double | 8 |
| 8 | long | 8 |
每种数据类型都有属于自己的特点、应用场景、和独特功能。
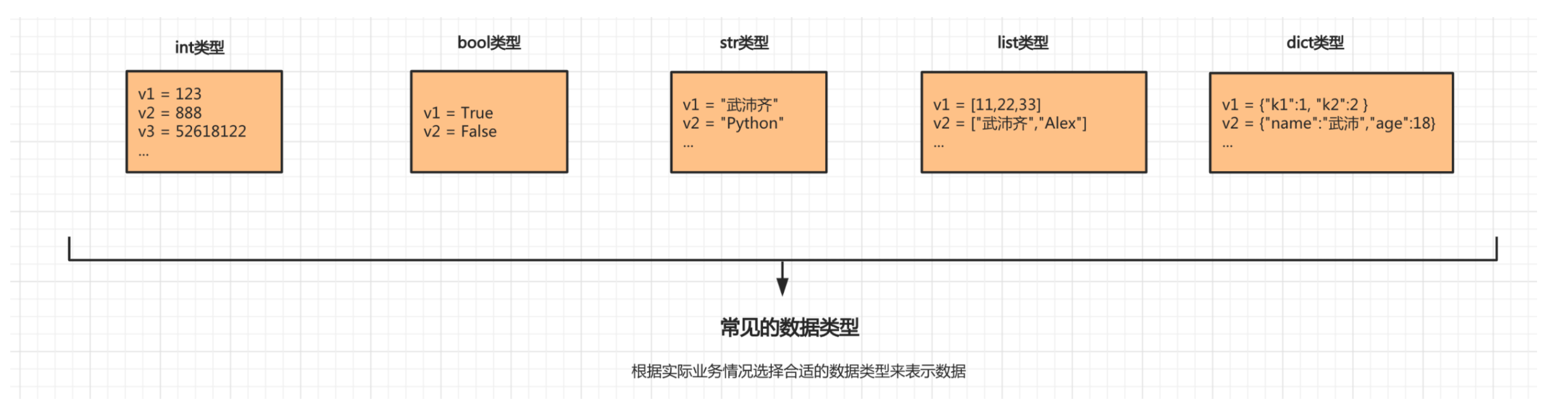
python是一门动态类型的编程语言,他不需要专门的对变量进行定义,当他的值为什么类型,他即为什么类型。
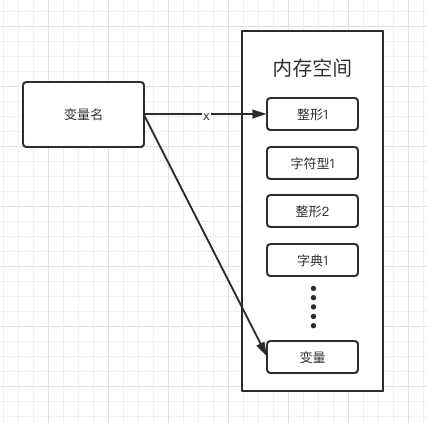
当变量名指向整形的时候,在内存中赋予其整形的内存空间大小,当同一个变量名指向其他类型的时候,又会在内存空间的另一个地方开辟另一个空间来存放。
2 整形
整型其实就是十进制整数的统称,比如:1、68、999都属于整型。他一般用于表示 年龄、序号等纯整数的场景。
2.1 定义方式
number = 10
age = 99
2.2 独有功能
整形只有一个独有功能,即使用.bit_length(),显示将整形转为二进制后有多少位。
v1 = 5
print(bin(v1)) # 0b101
# 调用v1(int)的独有功能,获取v1的二进制表示有多少个位组成。
result1 = v1.bit_length()
print(result1) # 3
v2 = 10
print(bin(10)) # 0b1010
# 调用v2(int)的独有功能,获取v2的二进制表示有多少个位组成。
result2 = v2.bit_length()
print(result2) # 4
2.3 公共功能
整形的公共功能就是加减乘除。
v1 = 4
v2 = 8
v3 = v1 + v2
2.4 转换
在项目开发和面试题中经常会出现一些 "字符串" 和 布尔值 转换为 整型的情况。
# 布尔值转整型
n1 = int(True) # True转换为整数 1
n2 = int(False) # False转换为整数 0
# 字符串转整型 base=几进制
v1 = int("186",base=10) # 把字符串看成十进制的值,然后再转换为 十进制整数,结果:v1 = 186
v2 = int("0b1001",base=2) # 把字符串看成二进制的值,然后再转换为 十进制整数,结果:v1 = 9 (0b表示二进制)
v3 = int("0o144",base=8) # 把字符串看成八进制的值,然后转换为 十进制整数,结果:v1 = 100 (0o表示八进制)
v4 = int("0x59",base=16) # 把字符串看成十六进制的值,然后转换为 十进制整数,结果:v1 = 89 (0x表示十六进制)
# 浮点型(小数)
v1 = int(8.7) # 8 会丢掉小数点后的数据
二进制、八进制、十进制、十六进制 规则存储的字符串,可以轻松的通过int转换为十进制的整数。
2.5 其他 -> python2与3的差别
2.5.1 长整形
- Python3:整型(无限制)
- Python2:整型、长整形
在python2中跟整数相关的数据类型有两种:int(整型)、long(长整型),他们都是整数只不过能表示的值范围不同。
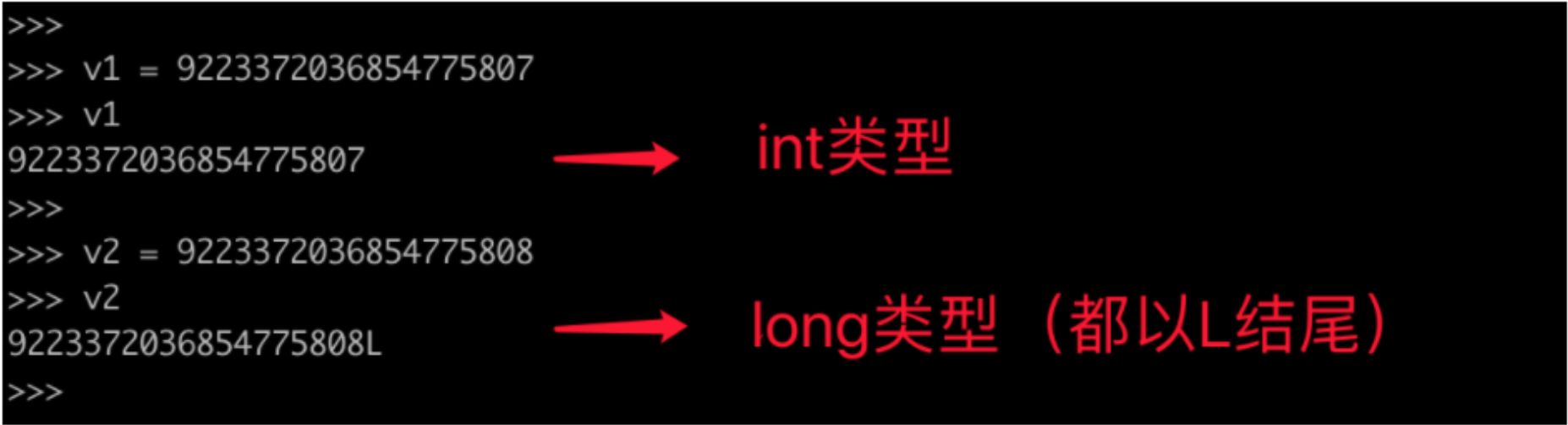
- int,可表示的范围:-9223372036854775808~9223372036854775807
- long,整数值超出int范围之后自动会转换为long类型(无限制)。
在python3中去除了long只剩下:int(整型),并且 int 长度不在限制。
2.5.2 整除
在python2中整形除以整形,也会得到一个整形,即丢掉小数点后的数字,在python3中进行了优化。
-
Python3:
v1 = 9/2 print(v1) # 4.5# python3 中整除 v1 = 9//2 print(v1) # 4 -
Python2:
v1 = 9/2 print(v1) # 4# python2中可以通过引入division来达到不整除 from __future__ import division v1 = 9/2 print(v1) # 4.5
3 布尔类型
布尔类型,常用在判断中,它就只有两个值:True和False
3.1 定义
demo1 = False
demo2 = True
3.2 独有功能
无
3.3 公共功能
boolean类型做运算时,会转换为整形进行
v1 = True + True
print(v1) # 2
3.4 转换
其他类型转换为布尔值的情景,只要记住一个规律即可。
整数0、空字符串、空列表、空元组、空字典转换为布尔值时均为False
其他均为True
案例
v1 = bool(0) # False
v2 = bool(-10) # True
v3 = bool(10) # True
v4 = bool("废物") # True
v5 = bool("") # Flase
v6 = bool(" ") # Flase
v7 = bool([]) # [] 表示空列表 Flase
v8 = bool([11,22,33]) # [11,22,33] 表示非空列表 True
v9 = bool({}) # {} 表示空字典 False
v10 = bool({"name":"kinght","age":18}) # {"name":"kinght","age":18} 表示非空字典 True
3.5 其他
3.5.1 做条件自动转换
如果在 if 、while 条件后面写一个值当做条件时,他会默认转换为布尔类型,然后再做条件判断。
if 值:
pass
while 值:
pass
案例:
if 0:
print("太六了")
else:
print(999)
if "kinght":
print("你好")
if "amber":
print("你是傻逼?")
else:
print("你是逗比?")
while 1>9:
pass
4 字符串类型
字符串,我们平时会用他来表示文本信息。例如:姓名、地址、自我介绍等。
4.1 定义
v1 = "包治百病"
v2 = '包治百病'
v3 = "包'治百病"
v4 = '包"治百病'
v5 = """
吵架都是我的错,
因为大家打不过。
"""
# 三个引号,可以支持多行/换行表示一个字符串,其他的都只能在一行中表示一个字符串。
4.2 独有功能
字符串的独有功能有48个,目前只介绍其中常用的18个。
# 使用功能的方式
## 基本格式1
"xxxxx".功能(...)
## 基本格式2
v1 = "xxxxx"
v1.功能(...)
4.2.1 判断字符串
判断字符串是否以 XX 开头?得到一个布尔值
# 案例1
v1 = "叨逼叨的一天,烦死了"
result = v1.startswith("叨逼叨的一天")
print(result) # 值为True
# 案例2
v1 = input("请输入住址:")
if v1.startswith("北京市"):
print("北京人口")
else:
print("非北京人口")
判断字符串是否以 XX 结尾?得到一个布尔值
# 案例1
v1 = "叨逼叨的一天,烦死了"
result = v1.endswith("烦死了")
print(result) # 值为True
# 案例2
address = input("请输入地址:")
if address.endswith('村'):
print("农业户口")
else:
print("非农户口")
判断字符串是否为十进制整数?得到一个布尔值
# 案例1
v1 = "1238871"
result = v1.isdecimal()
print(result) # True
# 案例2 -> 两个数相加。
v1 = input("请输入值:") # ”666“
v2 = input("请输入值:") # ”999“
if v1.isdecimal() and v2.isdecimal():
data = int(v1) + int(v2)
print(data)
else:
print("请正确输入数字")
## 这里不能使用isdigit
### isdigit 会把某些字符也判断成整数
v1 = "123"
print(v1.isdecimal()) # True
v2 = "①"
print(v2.isdecimal()) # False
v3 = "123"
print(v3.isdigit()) # True
v4 = "①"
print(v4.isdigit()) # True
4.2.2 字符串变换
去除字符串两边的 空格、换行符、制表符或去掉指定字符,得到一个新字符串
在输入中,有一些看不到的符号,例如空格、换行符\n、制表符\t,都可以通过strip()去掉
# 案例1
##将msg两边的空白去掉,得到"H e ll o啊,树哥"
msg = " H e ll o啊,树哥 "
data = msg.strip()
print(data) # H e ll o啊,树哥
## 只去除左边的空白
msg = " H e ll o啊,树哥 "
data = msg.lstrip()
print(data) # H e ll o啊,树哥
## 只去除右边的空白
msg = " H e ll o啊,树哥 "
data = msg.rstrip()
print(data) # H e ll o啊,树哥
# 案例2
code = input("请输入4位验证码:") # FB87 输入带空格,导致比较不准
data = code.strip()
if data == "FB87":
print('验证码正确')
else:
print("验证码错误")
也可以通过在strip(指定内容)去掉制定的符号。
# 将msg两边的哥去掉
msg = "哥H e ll o啊,树哥"
data = msg.strip("哥")
print(data) # H e ll o啊,树
# 只去除左边的哥
msg = "哥H e ll o啊,树哥"
data = msg.lstrip("哥")
print(data) # H e ll o啊,树哥
# 只去除右边的哥
msg = "哥H e ll o啊,树哥"
data = msg.rstrip("哥")
print(data) # 哥H e ll o啊,树
字符串首字母变大写,得到一个新的字符串
msg = 'absdaw'.capitalize()
print(msg) # Absdaw
字符串变大写,得到一个新字符串
# 案例1
msg = "my name is oliver queen"
data = msg.upper()
# 新生成大写值,不改变原来字符串
print(msg) # my name is oliver queen
print(data) # 输出为:MY NAME IS OLIVER QUEEN
# 案例2
code = input("请输入4位验证码:") # FB88 fb88
value = code.upper() # FB88
data = value.strip() # FB88
if data == "FB87":
print('验证码正确')
else:
print("验证码错误")
# 注意事项
"""
code的值"fb88 "
value的值"FB88 "
data的值"FB88"
"""
字符串变小写,得到一个新字符串
# 案例1
msg = "My Name Is Oliver Queen"
data = msg.lower()
print(data) # 输出为:my name is oliver queen
# 案例2
code = input("请输入4位验证码:")
value = code.strip().lower()
if value == "fb87":
print('验证码正确')
else:
print("验证码错误")
字符串内容替换,得到一个新的字符串
# 案例1
data = "你是个好人,但是好人不合适我"
value = data.replace("好人","贱人")
print(data) # "你是个好人,但是好人不合适我"
print(value) # "你是个贱人,但是贱人不合适我"
# 案例2
video_file_name = "高清无码爱情动作片.mp4"
new_file_name = video_file_name.replace("mp4","avi") # "高清无码爱情动作片.avi"
final_file_name = new_file_name.replace("无码","步兵") # "高清步兵爱情动作片.avi"
print(final_file_name)
# 案例3 -> 使用功能的时候,原变量不会被修改
video_file_name = "高清无码爱情动作片.mp4"
new_file_name = video_file_name.replace("mp4","avi") # "高清无码爱情动作片.avi"
final_file_name = video_file_name.replace("无码","步兵") # "高清步兵爱情动作片.mp4"
print(final_file_name)
# 案例4
content = input("请输入评论信息") # alex是一个草包
content = content.replace("草","**") # alex是一个**包
content = content.replace("泥马","***") # alex是一个**包
print(content) # alex是一个**包
# 案例5 -> 屏蔽敏感词系统
# 让用户输入一段文本,请实现将文本中的敏感词 `苍老师`、`波波老师`替换为 `***`,最后并输入替换后的文本。
Sensitive_words=['苍老师','苍老师']
user_speak = input("请输入文本:")
for replace in Sensitive_words:
user_speak=user_speak.replace(replace,"***")
print(user_speak)
4.2.3 字符串切割与拼接
字符串切割,得到一个列表
使用方法
.split("切割字符",切几个) # 从左往右切,切几个不填默认全切
.rsplit("切割字符",切几个) # 从右往左切,切几个不填默认全切
案例:
# 案例1
data = "武沛齐|root|wupeiqi@qq.com"
result = data.split('|') # ["武沛齐","root","wupeiqi@qq.com"]
print(data) # "武沛齐|root|wupeiqi@qq.com"
print(result) # 输出 ["武沛齐","root","wupeiqi@qq.com"] 根据特定字符切开之后保存在列表中,方便以后的操作
# 案例2
# 对用户输入的数据使用"+"切割,判断输入的值是否都是数字?(提示:用户输入的格式必须是以下+连接的格式,如 5+9 、alex+999)
result = input("请输入+连接的格式:")
result = result.split("+")
for i in result:
if i.isdecimal():
pass
else:
print("输入值不都是整数")
break
else:
print("输入值都是整数")
指定切几个
# 从左往右切一个
# 案例1
blog_url = 'yzc.blog
# 从左往右切割1个.
host_3 = blog_url.sp
print(host_3) # ['yzc', 'blog.geekxk.com']
# 从左往右切割2个.
host_2 = blog_url.sp
print(host_2) # ['yzc', 'blog', 'geekxk.com']
# 从右往左切1个
host_r = blog_url.r
print(host_r) # ['yzc.blog.geekxk', 'com']
# 案例2 -> 识别后缀名
file_path = "xxx/xxxx/xx.xx/xxx.mp4"
data_list = file_path.rsplit(".",1) # ["xxx/xxxx/xx.xx/xxx","mp4"]
data_list[0]
data_list[1]
字符串拼接,得到一个新的字符串
data_list = ["alex","是","大帅比"]
v1 = "_".join(data_list) # alex_是_大帅比
print(v1)
格式化字符串,得到新的字符串
前文在标准输出里提到过。格式化字符串的三种方式
# 方式一
name = "{0}的喜欢干很多行业,例如有:{1}、{2} 等"
data = name.format("老王","护士","嫩模")
print(data) # 老王的喜欢干很多行业,例如有:护士、嫩模 等
print(name) # "{0}的喜欢干很多行业,例如有:{1}、{2} 等"
# 方式二
name = "{}的喜欢干很多行业,例如有:{}、{} 等"
data = name.format("老王","护士","嫩模")
print(data) # 老王的喜欢干很多行业,例如有:护士、嫩模 等
# 方式三
name = "{name}的喜欢干很多行业,例如有:{h1}、{h2} 等"
data = name.format(name="老王",h1="护士",h2="嫩模")
print(data) # 老王的喜欢干很多行业,例如有:护士、嫩模 等
4.2.4 字符串转换字节类型
data = "嫂子" # unicode,字符串类型
# 在内存中存放是用unicode,如果存储到硬盘中,需要转存为utf-8编码或gbk编码
# 编码
v1 = data.encode("utf-8") # utf-8,字节类型
v2 = data.encode("gbk") # gbk,字节类型
print(v1) # b'\xe5\xab\x82 \xe5\xad\x90' 三个字节一个汉字
print(v2) # b'\xc9\xa9 \xd7\xd3' 两个字节一个汉字
# 解码
s1 = v1.decode("utf-8") # 嫂子
s2 = v2.decode("gbk") # 嫂子
print(s1)
print(s2)
4.2.5 将字符串内容居中、居左、居右展示
v1 = "王老汉"
# data = v1.center(21, "-")
# print(data) #---------王老汉---------
# data = v1.ljust(21, "-")
# print(data) # 王老汉------------------
# data = v1.rjust(21, "-")
# print(data) # ------------------王老汉
4.2.6 填充0
处理二进制数据,为了方便,让计算机自动在数值前面填充0
# 应用场景:处理二进制数据
data = "101" # "00000101"
v1 = data.zfill(8) # 将数值填充到8位,已有3位前面添加5个0
print(v1) # "00000101"
4.2.7 查询全部字符串独有功能
在pycharm编辑器中,输入str,然后安装windwos ctrl或者mac command键鼠标点击str即可查看python的关于字符串的源代码。
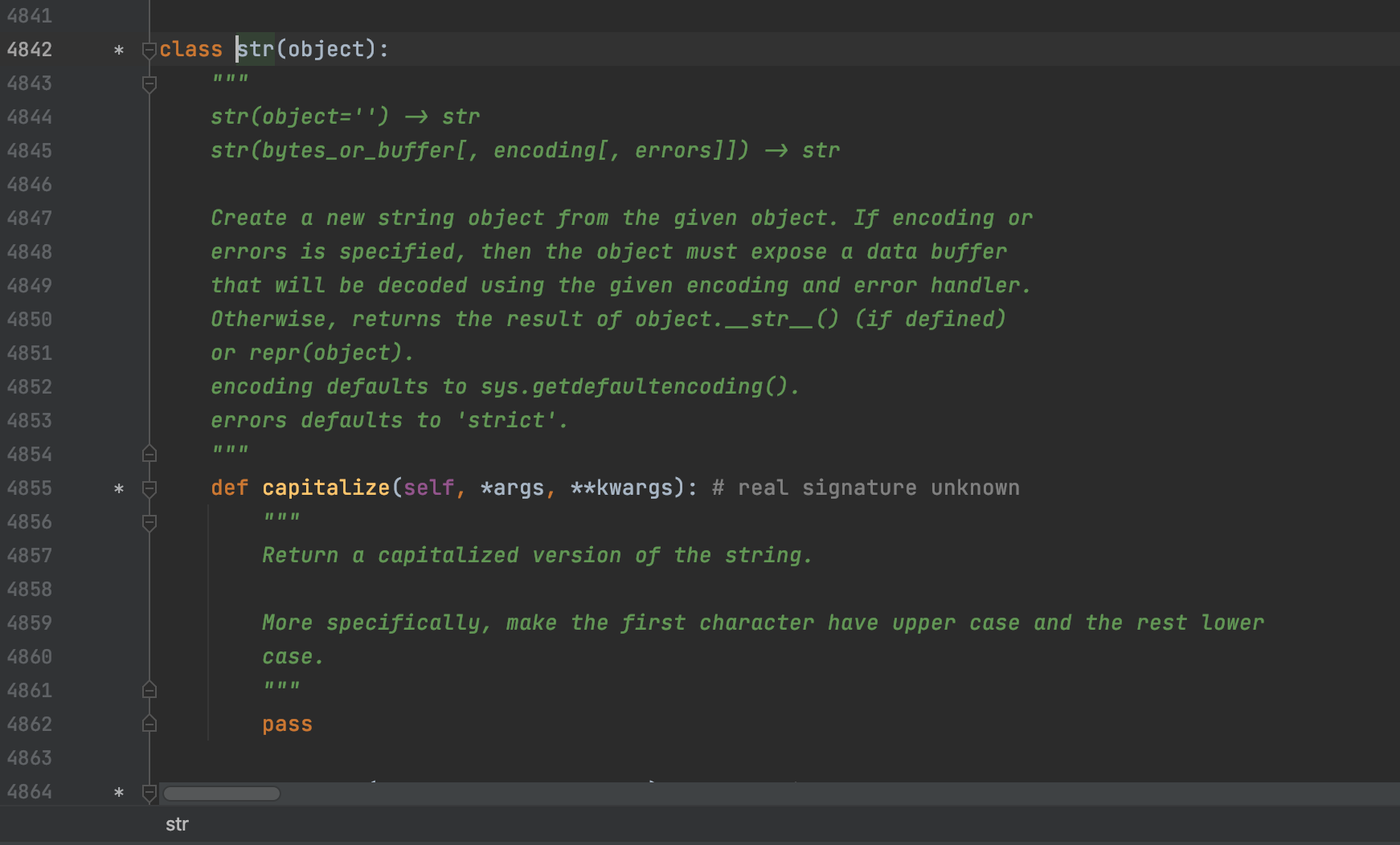
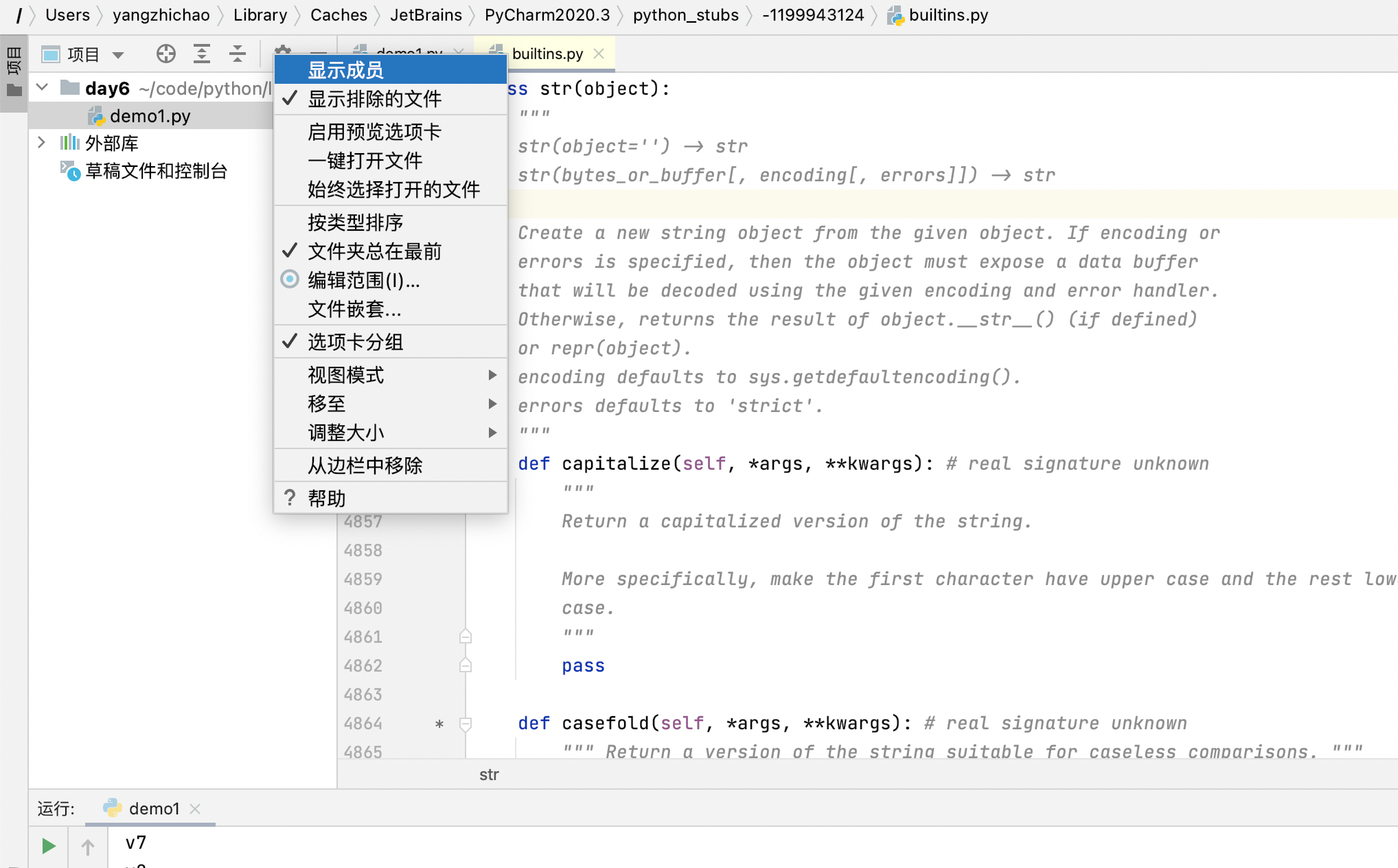
想要更方便的查看,鼠标选到 class str里面,然后点击小齿轮,打开显示成员
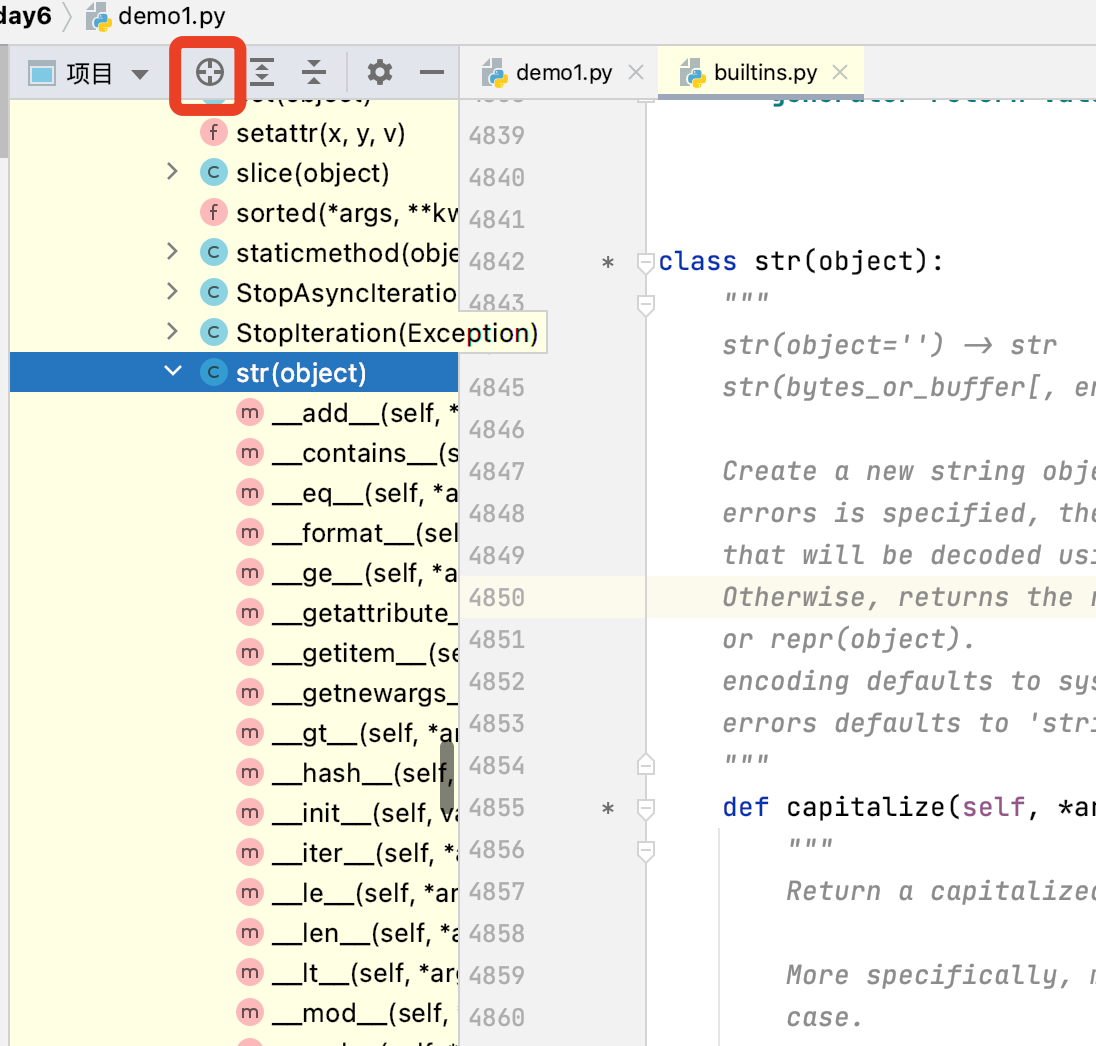
然后再点击定位小图标,就会显示str拥有的独有功能
4.3 公共功能
4.3.1 加减运算
# 相加:字符串 + 字符串 == 字符串拼接
v1 = "abc" + "def"
print(v1) # abcdef
# 相乘:字符串 * 整数 == 重复多次字符串
v1 = "abc" *3
print(v1) # abcabcabc
4.3.2 字符串的长度
长度使用len()来计算。
data = "asdljkharuiasudjkasiufhoiwhrlawiohawlheawio"
value = len(data)
print(value) # 43
4.3.3 字符串索引取字符
字符串能通过索引来进行取值,而字符串是一个元数据,不可变类型,在内部存储时不允许对内部元素修改,若要改动字符串中内容,则内存会直接销毁其对应的引用,另寻一块空间建立引用(相关知识后续文章会进行补充)。
字符串索引 -> 相当于对字符串的字符进行排序,从0开始
message = "来做点py交易呀"
# 0 1 2345 6 7 -> 正序
# ... -3 -2 -1 -> 倒叙
print(message[0]) # "来"
print(message[1]) # "做"
print(message[2]) # "点"
print(message[-1]) # 呀
print(message[-2]) # 易
print(message[-3]) # 交
案例:
# 案例
# 顺序展示message元素
message = "来做点py交易呀"
index = 0
while index < len(message):
value = message[index]
print(value)
index += 1
# 倒叙展示message元素
message = "来做点py交易呀"
index = len(message) - 1
while index >=0:
value = message[index]
print(value)
index -= 1
4.3.4 获取字符串中的子序列,切片
字符串切片遵循:遵循前取后不取
# 案例1
message = "来做点py交易呀"
print(message[0:2]) # "来做"
print(message[3:7]) # "py交易" -> 前取后不取
print( message[3:] ) # "py交易呀"
print( message[:5] ) # "来做点py"
print(message[4:-1]) # "y交易"
print(message[4:-2]) # "y交"
print( message[4:len(message)] ) # "y交易呀"
# 案例2
message = "来做点py交易呀"
value = message[:3] + "Python" + message[5:]
print(value)
4.3.5 步长
步长 == 切片范围内,隔几步取一次
name = "生活不是电影,生活比电影苦"
# 前两个值表示区间范围,最有一个值表示步长
print( name[ 0:5:2 ] ) # 输出:生不电 【取值序号0-5,两个值取一个】
# 区间范围的前面不写则表示起始范围为0开始
print( name[ :8:2 ] ) # 输出:生不电, 【取值范围:从头开始到索引8,两个取一个】
# 取值范围后面不写则是取到末尾
print( name[ 2::2 ] ) # 输出:不电,活电苦【取值范围:从索引2到结尾,两个取一个】
print( name[ 2::3 ] ) # 输出:不影活影【取值范围:从索引2到结尾,三个取一个】
# 区间范围不写表示整个字符串
print( name[ ::2 ] ) # 输出:生不电,活电苦 【取值范围:整个字符串,两个取一个】
# 步长为负数,则是倒序
print( name[ ::-1 ] ) # 输出:苦影电比活生,影电是不活生 【取值范围:整个字符串,倒序】
# 步长为负数,则是倒序
print( name[ ::-2 ] ) # 输出:苦电活,电不生 【取值范围:整个字符串,倒序,两个取一个】
案例
name = "生活不是电影,生活比电影苦"
print(name[8:1:-1]) # 输出:活生,影电是不 【倒序】
print(name[-1:1:-1]) # 输出:苦影电比活生,影电是不 【倒序】
# 面试题:给你一个字符串,请将这个字符串翻转。
value = name[-1::-1]
print(value) # 苦影电比活生,影电是不活生
4.3.6 循环
while循环
while循环是之前已经详细介绍过,这里不做过多的赘述了。
message = "来做点py交易呀"
index = 0
while index < len(message):
value = message[index]
print(value)
index += 1
for循环
for循环,又被称为迭代循环(取值循环),是python提供的第二种循环机制,从理论上for循环能做的事情,while循环都能做,for循环在循环取值上面比while更加简便,他可以将内部的值逐一取出,都遍历取出完成后,也能自动结束。
message = "来做点py交易呀"
for char in message:
print(char)
for循环的嵌套用法
for a in range(1,10):
for b in range(1,10):
print('{}x{}={}'.format(a,b,a*b))
range()函数
range(),这是一个在python2就有的功能,他的功能是生成从0开始的数组,括号里是多少,就生成序号到多少的列表
# 指定元素个数生成列表 -> 0-9 10个数
range(10) # [0,1,2,3,4,5,6,7,8,9]
# 指定元素序号生成列表 -> 整数1-9 同样遵循前取后不取
range(1,10) # [1,2,3,4,5,6,7,8,9]
# range可以指定步长
range(1,10,2) # [1,3,5,7,9]
# range步长为负数则是倒序
range(10,1,-1) # [10,9,8,7,6,5,4,3,2]
这是一个在python2就有的功能,但range作为列表而言,一旦数字过大,对于内存是一种负担。

Python3 做了相对应到优化,range() 函数返回的是一个可迭代对象(类型是对象),而不是列表类型, 所以打印的时候不会打印列表,这样做内存空间优化了,使用并不会有什么区别

案例
使用range限制登录次数
sys_name = 'admin'
sys_pwd = 'admin'
for x in range(3):
name = input("请输入账号:")
pwd = input('请输入密码:')
if(name == sys_name and pwd == sys_pwd):
print("密码正确")
break
else:
print("密码错误{}次,还有{}次机会".format((x+1),(2-x)))
else:
print("账号验证错误次数过多,请联系管理员找回密码")
循环的应用场景
- while,一般在做无限制(未知)循环此处时使用。
# 用户输入一个值,如果不是整数则一直输入,直到是整数了才结束。
num = 0
while True:
data = input("请输入内容:")
if data.isdecimal():
num = int(data)
break
else:
print("输入错误,请重新输入!")
- for循环,一般应用在已知的循环数量的场景。
for i in range(30):
print(message[i])
他们都适用于break和continue关键字。
4.4 转换
字符串的类型转换其实是一件很无意义的事情。
data_list = ["kinght","aym",999]
data = str(data_list)
print(data)
# 把列表整体'["alex","eric",999]'放入字符串 -> 无意义
字符串转换唯一的应用场景可能就是
num = 999
data = str(num)
print(data) # "999"
4.5 其他
这里再次强调,字符串是不可变类型,改变值==改变字符串
demo1 = 'abcdefg'
print(id(demo1)) # 140427044152816
demo1 = 'abcdfeg'
print(id(demo1)) # 140426774570672
id可以查看对于变量的内存地址。