Python开发-041_数据库查询条件
前期数据库准备
# 创建数据库
MariaDB [(none)]> create database test_demo;
# 进入数据库
MariaDB [(none)]> use test_demo;
# 数据表准备
create table emp(
id int not null unique auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male',
age int(3) unsigned not null default 25,
hire_date date not null, # 入职时间
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int,
depart_id int
);
# 插入记录
insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values('kinght','male',18,'20210628','leader',20000,401,1),
# 渗透测试
('amber','female',24,'20220628','PTE',16000,401,1),
('access','male',46,'20220527','PTE',22000,401,1),
('qumen','male',21,'20210614','PTE',20000,401,1),
('dreams','male',23,'20210428','PTE',18000,401,1),
# 安全服务
('kasa','male',45,'20220628','SSE',18000,402,2),
('ciu','female',32,'20211111','SSE',16000,402,2),
('pica','male',21,'20220412','SSE',14000,402,2),
('ddleam','male',32,'20210722','SSE',15000,402,2),
# 安全运营
('faty','male',33,'20211118','SOE',6000,403,3),
('case','male',45,'20211225','SOE',8000,403,3),
('deft','male',27,'20201226','SOE',8000,403,3),
('legit','male',31,'20220822','SOE',6000,403,3),
('rigth','male',28,'20210721','SOE',7000,403,3),
('lisa','female',22,'20210122','SOE',5000,403,3),
('fofa','male',24,'20210425','SOE',7000,403,3),
('kingboy','male',37,'20210224','SOE',6000,403,3),
('lepr','male',31,'20200716','SOE',7000,403,3);
如果表格展示数据会导致错乱,可以使用\G分行格式化展示
MariaDB [test_demo]> select * from emp \G;
*************************** 1. row ***************************
id: 1
name: kinght
sex: male
age: 18
hire_date: 2021-06-28
post: leader
post_comment: NULL
salary: 20000.00
office: 401
depart_id: 1
*************************** 2. row ***************************
id: 2
name: amber
sex: female
age: 24
hire_date: 2022-06-28
post: PTE
post_comment: NULL
salary: 16000.00
office: 401
depart_id: 1
*************************** 3. row ***************************
# 篇幅过长 后面省略
由于我们将所有的编码统一成为了UTF-8,而部分电脑由于版本太老并不支持UTF-8导致无法显示,所以可以改为GBK
1 SQL语句的书写建议
1.2 书写顺序建议
SQL语句的执行顺序和书写顺序其实是不同的
书写顺序:
select id,name from emp where id>3;
执行顺序:
1.先找到对应表 from emp
2.在找到符合筛选条件的字段 where id>3
3.在提取对应的数据 id,name
所以推荐书写方式
1.首先使用 select * 占位,补全其他的语句
2.再使用 * 替换掉对应数据的字段
1.2 Mysql的注释
-- 注释
# 注释
2 where约束条件
作用:对整体数据进行一个筛选操作
案例:
# 1.查询id大于等于3小于等于6的数据
select id,name from emp where id>=3 and id<=6;
select id,name from emp where id between 3 and 6; # betwenn在什么和什么之间
# 2.查询薪资18000、20000、22000的数据
select * from emp where salary=18000 or salary=20000 or salary=22000;
select * from emp where salary in (18000,20000,22000); # 可使用成员运算
# 3.查询员工姓名中包含字母a的员工姓名和薪资
## 模糊查询 like %(匹配任意多个字符) _(匹配任意单个字符)
select name,salary from emp where name like '%a%';
# 4.查询员工姓名由4个字符组成的 姓名和薪资
select name,salary from emp where name like '____';
select name,salary from emp where char_length(name) = 4; # char_length计算字符长度
# 5.查询id小于3或者id大于6的数据
select * from emp where id not between 3 and 6;
select * from emp where id<3 or id>6;
# 6.查询薪资不在18000、20000、22000的数据
select * from emp where salary not in (18000,20000,22000);
# 7.查询岗位描述为空的姓名和职位
select name,post from emp where post_comment=NULL; # 错误 查询NULL不能使用=号得使用is
select name,post from emp where post_comment is NULL;
3 group by 分组
分组顾名思义按照某一条件对条件相同的部分进行组合,默认输出是每组第一行数据(未开启严格模式)
# 按照部门进行分组
MariaDB [test_demo]> select * from emp group by post;
+----+--------+--------+-----+------------+--------+--------------+----------+--------+-----------+
| id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+--------+--------+-----+------------+--------+--------------+----------+--------+-----------+
| 1 | kinght | male | 18 | 2021-06-28 | leader | NULL | 20000.00 | 401 | 1 |
| 2 | amber | female | 24 | 2022-06-28 | PTE | NULL | 16000.00 | 401 | 1 |
| 10 | faty | male | 33 | 2021-11-18 | SOE | NULL | 6000.00 | 403 | 3 |
| 6 | kasa | male | 45 | 2022-06-28 | SSE | NULL | 18000.00 | 402 | 2 |
+----+--------+--------+-----+------------+--------+--------------+----------+--------+-----------+
4 rows in set (0.00 sec)
在分组之后,最小可操作单位应该是组 而不是组内某个数据 上诉命令在未设置严格模式的情况下 默认返回第一条数据,如果设置了严格模式会直接报错
# 开启分组严格模式
MariaDB [test_demo]> set global sql_mode='strict_trans_tables,only_full_group_by';
# 重启客户端生效
MariaDB [test_demo]> exit;
[root@localhost ~]# mysql
MariaDB [(none)]> show variables like '%mode';
+--------------------------+----------------------------------------+
| Variable_name | Value |
+--------------------------+----------------------------------------+
| innodb_autoinc_lock_mode | 1 |
| innodb_strict_mode | OFF |
| old_mode | |
| pseudo_slave_mode | OFF |
| slave_exec_mode | STRICT |
| sql_mode | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES |
+--------------------------+----------------------------------------+
6 rows in set (0.00 sec)
# 再次执行就报错
MariaDB [test_demo]> use test_demo;
MariaDB [test_demo]> select * from emp group by post;
ERROR 1055 (42000): 'test_demo.emp.id' isn't in GROUP BY
分组完成后,只能拿到分组的数据 其他字段不能直接获取
MariaDB [test_demo]> select post from emp group by post;
+--------+
| post |
+--------+
| leader |
| PTE |
| SOE |
| SSE |
+--------+
4 rows in set (0.00 sec)
可以通过聚合函数运算获取每个部门的信息
# 1.获取每个部门的最高薪资
select post,max(salary) from emp group by post; # max()计算括号内的最大值
## as可以为表头取别名
MariaDB [test_demo]> select post as '部门',max(salary) as '最高薪资' from emp group by post;
+--------+--------------+
| 部门 | 最高薪资 |
+--------+--------------+
| leader | 20000.00 |
| PTE | 22000.00 |
| SOE | 8000.00 |
| SSE | 18000.00 |
+--------+--------------+
4 rows in set (0.00 sec)
### as也可以省略不写 不过不推荐,会导致语义不明确
MariaDB [test_demo]> select post '部门',max(salary) '最高薪资' from emp group by post;
# 2.获取每个部门最低薪资
select post,min(salary) from emp group by post;
# 3.获取每个部门平均薪资
select post,avg(salary) from emp group by post;
# 4.获取每个部门工资总和
select post,sum(salary) from emp group by post;
# 5.获取每个部门人数
## 聚合函数可以放其他的字段 (不能对None数据计数)
select post,count(id) from emp group by post;
# 6.查询分组之后的部门名称和每个部门所有的员工姓名
## group_concat 分组之后普通字段的值
select post,group_concat(name) from emp group by post;
+--------+---------------------------------------------------+
| post | group_concat(name) |
+--------+---------------------------------------------------+
| leader | kinght |
| PTE | amber,access,qumen,dreams |
| SOE | legit,rigth,lisa,fofa,kingboy,deft,case,faty,lepr |
| SSE | ddleam,pica,ciu,kasa |
+--------+---------------------------------------------------+
4 rows in set (0.00 sec)
## 还支持获取值之后的拼接操作
select post,group_concat(name,'_DSB') from emp group by post;
+--------+---------------------------------------------------------------------------------------+
| post | group_concat(name,'_DSB') |
+--------+---------------------------------------------------------------------------------------+
| leader | kinght_DSB |
| PTE | amber_DSB,access_DSB,qumen_DSB,dreams_DSB |
| SOE | legit_DSB,rigth_DSB,lisa_DSB,fofa_DSB,kingboy_DSB,deft_DSB,case_DSB,faty_DSB,lepr_DSB |
| SSE | ddleam_DSB,pica_DSB,ciu_DSB,kasa_DSB |
+--------+---------------------------------------------------------------------------------------+
4 rows in set (0.00 sec)
## 还支持同时拿多个字段
select post,group_concat(name,':',age) from emp group by post;
+--------+------------------------------------------------------------------------------+
| post | group_concat(name,':',age) |
+--------+------------------------------------------------------------------------------+
| leader | kinght:18 |
| PTE | amber:24,access:46,qumen:21,dreams:23 |
| SOE | legit:31,rigth:28,lisa:22,fofa:24,kingboy:37,deft:27,case:45,faty:33,lepr:31 |
| SSE | ddleam:32,pica:21,ciu:32,kasa:45 |
+--------+------------------------------------------------------------------------------+
4 rows in set (0.00 sec)
# 7.同级各部门年龄在30岁以上的平均薪资
select post,avg(salary) from emp where age>30 group by post;
+------+--------------+
| post | avg(salary) |
+------+--------------+
| PTE | 22000.000000 |
| SOE | 6600.000000 |
| SSE | 16333.333333 |
+------+--------------+
3 rows in set (0.00 sec)
分组注意事项
1.关键字 where 和 group by 同时出现,group by 必须在 where 后方
2.where 筛选条件后方不能使用聚合函数
select id,name,age from emp where max(salary)>3000; # 错误
3.当没有进行分组的时候,默认整体就是一组,可以使用聚合函数
select max(salary) from emp; # 正常运行
4 补充小知识
4.1 group_concat是分组之后用 concat就是分组之前用
MariaDB [test_demo]> select concat('name:',name),concat('Post:',post) from emp;
+----------------------+----------------------+
| concat('name:',name) | concat('Post:',post) |
+----------------------+----------------------+
| name:kinght | Post:leader |
| name:amber | Post:PTE |
| name:access | Post:PTE |
| name:qumen | Post:PTE |
| name:dreams | Post:PTE |
| name:kasa | Post:SSE |
| name:ciu | Post:SSE |
| name:pica | Post:SSE |
| name:ddleam | Post:SSE |
| name:faty | Post:SOE |
| name:case | Post:SOE |
| name:deft | Post:SOE |
| name:legit | Post:SOE |
| name:rigth | Post:SOE |
| name:lisa | Post:SOE |
| name:fofa | Post:SOE |
| name:kingboy | Post:SOE |
| name:lepr | Post:SOE |
+----------------------+----------------------+
4.2 as不光可以给字段名取别名也可以给表取别名
MariaDB [test_demo]> select emp.id,emp.name from emp; # 正常运行
# 给表取别名
MariaDB [test_demo]> select emp.id,emp.name from emp as t1;
ERROR 1054 (42S22): Unknown column 'emp.id' in 'field list' # 报错找不到emp.id
# 修改取值
MariaDB [test_demo]> select t1.id,t1.name from emp as t1; # 正常运行
4.3 SQL语句可以直接进行运算
# 查询每个人年薪
select name,salary*12 from emp;
5 having 分组后筛选
having语法与where相同,但它可以使用聚合函数
# 统计各部门年龄在30岁以上的员工平均工资并且保留平均薪资大于10000的部门
## 1.首先进行where筛选年龄大于30岁的
## 2.group by post 进行分组
## 3.having avg(salary)>10000 再次筛选年龄大于30岁的
## 4.最后返回查询条件查询post和avg(salary)输出
MariaDB [test_demo]> select post,avg(salary) from emp where age>30 group by post having avg(salary)>10000;
+------+--------------+
| post | avg(salary) |
+------+--------------+
| PTE | 22000.000000 |
| SSE | 16333.333333 |
+------+--------------+
2 rows in set (0.00 sec)
6 distinct 去重
一定要注意 必须是完全一样的数据才能去重! 不能忽略主键 有主键存在的情况下是不能去重的
# 有主键是无法去重的
MariaDB [test_demo]> select distinct id,salary from emp;
+----+----------+
| id | salary |
+----+----------+
| 1 | 20000.00 |
| 2 | 16000.00 |
| 3 | 22000.00 |
| 4 | 20000.00 |
| 5 | 18000.00 |
| 6 | 18000.00 |
| 7 | 16000.00 |
| 8 | 14000.00 |
| 9 | 15000.00 |
| 10 | 6000.00 |
| 11 | 8000.00 |
| 12 | 8000.00 |
| 13 | 6000.00 |
| 14 | 7000.00 |
| 15 | 5000.00 |
| 16 | 7000.00 |
| 17 | 6000.00 |
| 18 | 7000.00 |
+----+----------+
18 rows in set (0.00 sec)
# 去重的时候把主键去掉
MariaDB [test_demo]> select distinct salary from emp;
+----------+
| salary |
+----------+
| 20000.00 |
| 16000.00 |
| 22000.00 |
| 18000.00 |
| 14000.00 |
| 15000.00 |
| 6000.00 |
| 8000.00 |
| 7000.00 |
| 5000.00 |
+----------+
10 rows in set (0.00 sec)
7 order by 排序
# 对工资进行排序 从小到大 升序
MariaDB [test_demo]> select * from emp order by salary;
+----+---------+--------+-----+------------+--------+--------------+----------+--------+-----------+
| id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+---------+--------+-----+------------+--------+--------------+----------+--------+-----------+
| 15 | lisa | female | 22 | 2021-01-22 | SOE | NULL | 5000.00 | 403 | 3 |
| 10 | faty | male | 33 | 2021-11-18 | SOE | NULL | 6000.00 | 403 | 3 |
| 17 | kingboy | male | 37 | 2021-02-24 | SOE | NULL | 6000.00 | 403 | 3 |
| 13 | legit | male | 31 | 2022-08-22 | SOE | NULL | 6000.00 | 403 | 3 |
| 16 | fofa | male | 24 | 2021-04-25 | SOE | NULL | 7000.00 | 403 | 3 |
| 14 | rigth | male | 28 | 2021-07-21 | SOE | NULL | 7000.00 | 403 | 3 |
| 18 | lepr | male | 31 | 2020-07-16 | SOE | NULL | 7000.00 | 403 | 3 |
| 11 | case | male | 45 | 2021-12-25 | SOE | NULL | 8000.00 | 403 | 3 |
| 12 | deft | male | 27 | 2020-12-26 | SOE | NULL | 8000.00 | 403 | 3 |
| 8 | pica | male | 21 | 2022-04-12 | SSE | NULL | 14000.00 | 402 | 2 |
| 9 | ddleam | male | 32 | 2021-07-22 | SSE | NULL | 15000.00 | 402 | 2 |
| 7 | ciu | female | 32 | 2021-11-11 | SSE | NULL | 16000.00 | 402 | 2 |
| 2 | amber | female | 24 | 2022-06-28 | PTE | NULL | 16000.00 | 401 | 1 |
| 5 | dreams | male | 23 | 2021-04-28 | PTE | NULL | 18000.00 | 401 | 1 |
| 6 | kasa | male | 45 | 2022-06-28 | SSE | NULL | 18000.00 | 402 | 2 |
| 4 | qumen | male | 21 | 2021-06-14 | PTE | NULL | 20000.00 | 401 | 1 |
| 1 | kinght | male | 18 | 2021-06-28 | leader | NULL | 20000.00 | 401 | 1 |
| 3 | access | male | 46 | 2022-05-27 | PTE | NULL | 22000.00 | 401 | 1 |
+----+---------+--------+-----+------------+--------+--------------+----------+--------+-----------+
18 rows in set (0.00 sec)
# order by 默认为升序 完整语句是(asc为升序 由于默认也是升序就可以不写)
select * from emp order by salary asc;
# order by 降序
select * from emp order by salary desc;
order by可以添加多个条件进行排序
# 按照从左只有的顺序进行 先排序左边的第一个条件 如果有相同的 在相同的基础上进行第二个条件的排序
select * from emp order by salary desc,id asc;
# 先对工资进行排序降序 工资相同的按ID进行排序升序
8 limit 限制展示条数
在很多情况需要限制输出才能正常展示数据
例如:
上亿条数据 一起输出 会导致服务器卡死 需要限制输出的条数
渗透测试 SQL注入 某些点只能展示一条数据,想要看多条就需要使用limit(SQL注入后续章节会详细讲解)
针对数据过多的情况,通常都是采用分页处理
# 展示前三条数据
MariaDB [test_demo]> select * from emp limit 3;
+----+--------+--------+-----+------------+--------+--------------+----------+--------+-----------+
| id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+--------+--------+-----+------------+--------+--------------+----------+--------+-----------+
| 1 | kinght | male | 18 | 2021-06-28 | leader | NULL | 20000.00 | 401 | 1 |
| 2 | amber | female | 24 | 2022-06-28 | PTE | NULL | 16000.00 | 401 | 1 |
| 3 | access | male | 46 | 2022-05-27 | PTE | NULL | 22000.00 | 401 | 1 |
+----+--------+--------+-----+------------+--------+--------------+----------+--------+-----------+
3 rows in set (0.00 sec)
# 第一个参数是起始位置(初始序号为0) 第二个参数是条数
select * from emp limit 0,5; # 第一个参数开始取5个
select * from emp limit 5,5; # 第六个参数开始取5个
9 正则表达式
SQL语法支持正则表达式
select * from emp where name regexp '^k.*(h|t)$';
# k开头 .*任意多个 h或者t结尾的字符串
10 多表查询
案例需要需要两个新表,并且由于表名重合,建立新数据库demo2
create database demo2;
use demo2;
create table dep(
id int,
name varchar(20)
);
create table emp(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
# 插入数据
insert into dep values(200,'技术'),(201,'人力资源'),(202,'销售'),(203,'运营'),(205,'公关');
insert into emp(name,sex,age,dep_id) values ('kinght','male',22,200),('alex','female',48,201),('kavin','male',18,201),('ququ','male',28,202),('owen','male',18,203),('jerry','female',18,204);
10.1 拼表
我们为了方便存储将数据分为了多张表,但是展示的时候还是希望他们能组成一张表
# from 两张表 where 建立两张表的关系 emp.dep_id字段是指dep.id字段
select * from emp,dep where emp.dep_id = dep.id;
+----+--------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+----+--------+--------+------+--------+------+--------------+
| 1 | kinght | male | 22 | 200 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 3 | kavin | male | 18 | 201 | 201 | 人力资源 |
| 4 | ququ | male | 28 | 202 | 202 | 销售 |
| 5 | owen | male | 18 | 203 | 203 | 运营 |
+----+--------+--------+------+--------+------+--------------+
5 rows in set (0.00 sec)
sql语句深知此操作的重要性,为了保证语义提出了四种操作模式
'''
inner join 内连接
left join 左连接
right join 右连接
union 全连接
'''
# 1.inner join 内连接
# select 查询字段名 from 左表名 inner join 右表名 on 左表.对应字段 = 右表.对应字段
MariaDB [demo2]> select * from emp inner join dep on emp.dep_id = dep.id;
+----+--------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+----+--------+--------+------+--------+------+--------------+
| 1 | kinght | male | 22 | 200 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 3 | kavin | male | 18 | 201 | 201 | 人力资源 |
| 4 | ququ | male | 28 | 202 | 202 | 销售 |
| 5 | owen | male | 18 | 203 | 203 | 运营 |
+----+--------+--------+------+--------+------+--------------+
5 rows in set (0.00 sec)
# 内连接指拼接两张表中共有的数据部分 例如('jerry','female',18,204)就没有显示
# 2.left join 左连接
# select 查询字段名 from 左表名 left join 右表名 on 左表.对应字段 = 右表.对应字段
MariaDB [demo2]> select * from emp left join dep on emp.dep_id = dep.id;
+----+--------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+----+--------+--------+------+--------+------+--------------+
| 1 | kinght | male | 22 | 200 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 3 | kavin | male | 18 | 201 | 201 | 人力资源 |
| 4 | ququ | male | 28 | 202 | 202 | 销售 |
| 5 | owen | male | 18 | 203 | 203 | 运营 |
| 6 | jerry | female | 18 | 204 | NULL | NULL |
+----+--------+--------+------+--------+------+--------------+
6 rows in set (0.00 sec)
# 左表所有的数据都展示出来 没有对应项就是用NULL
# 3.right join 左连接
# select 查询字段名 from 左表名 right join 右表名 on 左表.对应字段 = 右表.对应字段
MariaDB [demo2]> select * from emp right join dep on emp.dep_id = dep.id;
+------+--------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+------+--------+--------+------+--------+------+--------------+
| 1 | kinght | male | 22 | 200 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 3 | kavin | male | 18 | 201 | 201 | 人力资源 |
| 4 | ququ | male | 28 | 202 | 202 | 销售 |
| 5 | owen | male | 18 | 203 | 203 | 运营 |
| NULL | NULL | NULL | NULL | NULL | 205 | 公关 |
+------+--------+--------+------+--------+------+--------------+
6 rows in set (0.00 sec)
# 右表所有的数据都展示出来 没有对应项就是用NULL
# 4.union 全连接使用方法
# union是联合语句使用的含义,本质与此案例无关
# 全连接是指左连接和右连接联合使用 顾 将左连接查询语句和右连接查询语句联合运行就是全连接
select * from emp left join dep on emp.dep_id = dep.id union select * from emp right join dep on emp.dep_id = dep.id;
10.2 子查询
将一个条件语句的结果当做另一个查询语句的条件使用
# 问题:查询技术部或者人力资源部的员工信息
# 解决方案:
MariaDB [demo2]> select id from dep where name='技术' or name='人力资源';
+------+
| id |
+------+
| 200 |
| 201 |
+------+
2 rows in set (0.00 sec)
MariaDB [demo2]> select id,name from emp where dep_id in (200,201);
+----+--------+
| id | name |
+----+--------+
| 1 | kinght |
| 2 | alex |
| 3 | kavin |
+----+--------+
3 rows in set (0.00 sec)
# 子查询简化方案
# 表的查询结果可以作为其他表的查询条件
# 也可以通过起别名的方式把它作为一张虚拟表和其他表关联
MariaDB [demo2]> select id,name from emp where dep_id in (select id from dep where name='技术' or name='人力资源');
+----+--------+
| id | name |
+----+--------+
| 1 | kinght |
| 2 | alex |
| 3 | kavin |
+----+--------+
3 rows in set (0.00 sec)
10.3 多表查询总结
只要是多表查询就可以使用子查询和拼表两种方案解决
TIPS:涉及到多表操作的时候一定要加上表的前缀
# 查询平均年龄在25岁以上的部门名称
## 连表操作思路
### 1.先拿到部门名称和员工表拼接的结果
MariaDB [demo2]> select * from emp inner join dep on emp.dep_id = dep.id;
+----+--------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+----+--------+--------+------+--------+------+--------------+
| 1 | kinght | male | 22 | 200 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 3 | kavin | male | 18 | 201 | 201 | 人力资源 |
| 4 | ququ | male | 28 | 202 | 202 | 销售 |
| 5 | owen | male | 18 | 203 | 203 | 运营 |
+----+--------+--------+------+--------+------+--------------+
5 rows in set (0.00 sec)
### 2.在此基础上进行分组
MariaDB [demo2]> select * from emp inner join dep on emp.dep_id = dep.id group by dep.name having avg(age)>25;
+----+------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+----+------+--------+------+--------+------+--------------+
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 4 | ququ | male | 28 | 202 | 202 | 销售 |
+----+------+--------+------+--------+------+--------------+
2 rows in set (0.00 sec)
### 3.只需要部门名称 注意:合表之后出现了两个name,要指出是哪个表的name
MariaDB [demo2]> select dep.name from emp inner join dep on emp.dep_id = dep.id group by dep.name having avg(age)>25;
+--------------+
| name |
+--------------+
| 人力资源 |
| 销售 |
+--------------+
2 rows in set (0.00 sec)
## 子查询操作
### 1.员工表分组查询出平均年龄大于25岁的部门编号
MariaDB [demo2]> select * from emp group by dep_id having avg(age)>25;
+----+------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------+--------+------+--------+
| 2 | alex | female | 48 | 201 |
| 4 | ququ | male | 28 | 202 |
+----+------+--------+------+--------+
2 rows in set (0.00 sec)
### 2.将其作为子查询结果查询表名
MariaDB [demo2]> select name from dep where id in (select dep_id from emp group by dep_id having avg(age)>25);
+--------------+
| name |
+--------------+
| 人力资源 |
| 销售 |
+--------------+
2 rows in set (0.00 sec)
10.4 多表查询补充关键字 exists
select * from emp where exists(select id from dep where id>300);
exists 只返回布尔值
括号内查询语句有值返回True 外部查询语句执行
括号内查询语句没有值返回False 外部查询语句不执行s
11 SQL强化练习
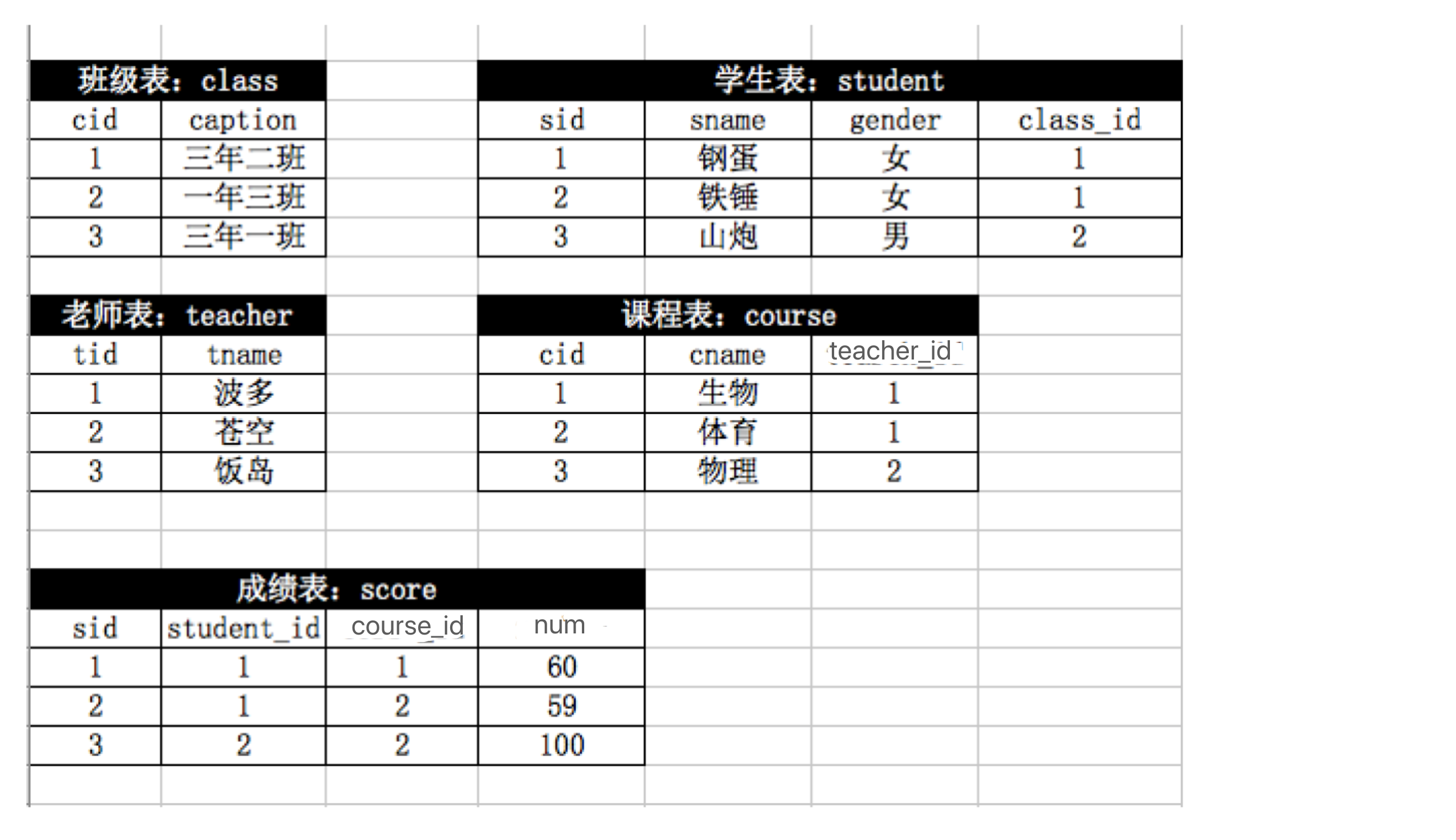
1 根据上图创建 数据库 & 表结构 并 录入数据(可以自行创造数据)
# 需求分析
班级表
cid
caption
学生表
sid
sname
gender
class_id(外键关联 class.cid)
教师表
tid
tname
课程表
cid
cname
teacher_id(外键关联 teacher.tid)
成绩表
sid
student_id(外键关联 student.sid)
course_id(外键关联 course.cid)
num
# 创建数据库 学校
MariaDB [(none)]> create database school;
MariaDB [(none)]> use school;
# 创建顺序 被关联从多到少 关联别人从0到多
## 创建班级表
create table class(
cid int primary key auto_increment,
caption varchar(32)
);
insert into class(caption) values('三年二班'),('一年三班'),('三年一班');
## 创建教师表
create table teacher(
tid int primary key auto_increment,
tname varchar(32)
);
insert into teacher(tname) values('波多'),('苍空'),('饭岛');
## 创建学生表
create table student(
sid int primary key auto_increment,
sname varchar(32),
gender enum('男','女') default '男',
class_id int,
foreign key(class_id) references class(cid)
on update cascade
on delete cascade
);
insert into student(sname,gender,class_id) values('钢蛋','女',1),('铁锤','女',1),('山炮','男',2),('铁牛','男',2);
## 创建课程表
create table course(
cid int primary key auto_increment,
cname varchar(16),
teacher_id int,
foreign key(teacher_id) references teacher(tid)
on update cascade
on delete cascade
);
insert into course(cname,teacher_id) values('生物',1),('体育',1),('物理',2),('化学',3);
## 创建成绩表
create table score(
sid int primary key auto_increment,
student_id int,
course_id int,
num int,
foreign key(student_id) references student(sid)
on update cascade
on delete cascade,
foreign key(course_id) references course(cid)
on update cascade
on delete cascade
);
insert into score(student_id,course_id,num) values(1,1,60),(1,2,59),(2,2,100),(1,3,95),(2,1,65),(2,3,86),(3,1,22),(3,2,100),(3,3,66),(3,4,99),(4,3,22),(4,1,33);
2.查询所有课程名称以及对应任课老师姓名
select cname as '课程名称',tname as '教师姓名' from course inner join teacher on course.teacher_id = teacher.tid;
3.查询平均成绩大于八十分的同学和平均成绩
# 连表
select * from score inner join student on score.student_id = student.sid;
# 分组使用聚合函数筛选平均分大于八十分的学生
select * from score inner join student on score.student_id = student.sid group by score.student_id having avg(score.num)>80;
# 输出结果
select student.sname as '学生名',avg(score.num) as '平均成绩' from score inner join student on score.student_id = student.sid group by score.student_id having avg(score.num)>80;
4.没有报饭岛老师课的学生姓名(没有成绩即为没报名)
# 分布查询
# 查询饭岛老师教授的课程编号
select cid from course inner join teacher on course.teacher_id = teacher.tid where teacher.tname='饭岛';
# 成绩表查询报了饭岛老师的学生id
## DISTINCT 去除重复数据 操作
select DISTINCT student_id from score where course_id = (select cid from course inner join teacher on course.teacher_id = teacher.tid where teacher.tname='饭岛');
# 学生表查询没有报饭岛老师的学生名字
select student.sname from student where sid not in (select student_id from score where course_id = (select cid from course inner join teacher on course.teacher_id = teacher.tid where teacher.tname='饭岛'));
5.化学和物理只选修其中一门的同学
# 查询化学和物理的cid
select course.cid from course where course.cname in ('物理','化学');
# 查询选择了化学和物理的学生信息
select * from score where score.course_id in (3,4);
select * from score where score.course_id in (select course.cid from course where course.cname in ('物理','化学'));
# 通过分组查询学生选了几门课获取只选修其中一门的学生id
select student_id from score where score.course_id in (select course.cid from course where course.cname in ('物理','化学')) group by student_id having count(course_id)=1;
# 将学生ID作为查询条件查询名字
select sname from student where sid in (select student_id from score where score.course_id in (select course.cid from course where course.cname in ('物理','化学')) group by student_id having count(course_id)=1);
6.查询挂科超过两门(包括两门的学生姓名和班级)
# 挂科两门的大佬
## 查询num<60不合格的将其根据学生分组 分组结果计算科目数 >= 2
select student_id from score where num < 60 group by student_id having count(num)>=2;
# 获取班级id和姓名
select * from student where sid in (select student_id from score where num < 60 group by student_id having count(num)>=2);
# 查询班级ID组表
## 这里由于需要使用右边的数据筛选左边的数据,所以采用右拼表的形式进行
## 将前面步骤查询的虚拟表使用as重命名为t1 参与拼表
select class.caption,t1.sname from class right join (select * from student where sid in (select student_id from score where num < 60 group by student_id having count(num)>=2))as t1 on class.cid = t1.class_id;